二进制安全面经
Last Update:
Word Count:
Read Time:
二进制安全面经
自己的面试经历
2021年1月腾讯科恩实习:一面挂
2021年12月深信服实习:已过,自己未去实习。
2022年10绿盟科技校招:应该一面挂
逆向
常见的壳子:
一、压缩壳: 1、UPX 2、ASPack 3、PECompact 4、RLPack 5、NSPack
二、保护壳: 1、ASProtect 2、Armadillo 3、EXECryptor 4、Themida 5、VMProtect
三、捆绑壳: MOleBox
花指令
花指令:目的是干扰ida和od等软件对程序的静态分析。使这些软件无法正常反汇编出原始代码。
常用的两类反汇编算法:
1.线性扫描算法:逐行反汇编(无法将数据和内容进行区分)
2.递归行进算法:按照代码可能的执行顺序进行反汇编程序。
比如:
1 | |
jmp垃圾填充
1 | |
多层jmp垃圾填充
永真条件跳转
利用jz和jnz的互补条件跳转指令来代替jmp
1 | |
call&ret构造花指令
call指令:将下一条指令地址压入栈,再跳转执行 ret指令:将保存的地址取出,跳转执行
清除花指令
手动清除:
手动通过ida打nop去除花指令
自动自动化花指令:
通过脚本进行查找特定的opcode,然后替换,一般对对jnx和jx的花指令进行自动化处理
1 | |
ref: https://blog.csdn.net/abel_big_xu/article/details/117927674
Windows
注入有哪几种方式?
SetwindowsHook
以调试方式打开进程,制造异常,在接管异常代理的代码里加入注入代码
CreateRemoteThread 和 Loadlibrary 将要执行的代码写在Dll里
CreateRemoteThread 和Writeprocessmemory 写汇编代码
修改PE文件导入表,添加Dll
修改PE文件入口,将入口指向要执行的代码处,执行完代码再执行正常代码
用哪些逆向工具?
olldbg、ida、windbg等。
Andoird
安卓一般逆向java还有armv8的c++动态链接库,常见
所使用的逆向工具:
android killer、apktool、ida等。
VMP 加壳示例
推荐一个 VMP 加壳程序 ADVMP ;
VMP 的核心原理是 自定义 Dalvik 和 ART 解释器 , 解释器解释 Smali 指令流 ; 该解释器是 VMP 加壳的核心原理 ;
解释器可以使用 Java 实现 , 也可以使用 C 实现 , 使用 Java 实现更容易被破解 ; 因此 , 解释器一般使用 C 实现 , 为了保护解释器不被快速定位 , 一般会使用 OLLVM 技术对解释器进行保护 , 增加逆向的难度 ;
Dex2C 加壳示例
推荐一个 Dex2C 加壳程序 dcc ;
Dex2C 加壳特征 : 获取到 DEX 文件后 , 其中被保护的函数 , 由 Java 函数变为了 Native 函数 ;
传统的编译原理 : 将代码进行词法 , 句法分析 , 生成二进制汇编代码 , 也就是机器码 ;
Dex2C 中, 将 Java 代码进行词法 , 句法分析 , 生成对应的 C / C++ 文件 , 然后交叉编译为 SO 动态库 ;
代码混淆
Ollvm混淆
OLLVM(Obfuscator-LLVM)是瑞士西北应用科技大学安全实验室发起的一个项目,是一套开源的针对LLVM的代码混淆工具,以增加对逆向工程的难度。github上地址是https://github.com/obfuscator-llvm/obfuscator,只不过仅更新到llvm的4.0,2017年开始就没在更新。
原版提供了3种混淆方式分别是控制流扁平化,指令替换,虚假控制流程,用起来都是加cflags的方式。下面简单说下这几种模式。
控制流扁平化
这个模式主要是把一些if-else语句,嵌套成do-while语句
-mllvm -fla:激活控制流扁平化
-mllvm -split:激活基本块分割。在一起使用时改善展平。
-mllvm -split_num=3:如果激活了传递,则在每个基本块上应用3次。默认值:1
指令替换
这个模式主要用功能上等效但更复杂的指令序列替换标准二元运算符(+ , – , & , | 和 ^)
-mllvm -sub:激活指令替换
-mllvm -sub_loop=3:如果激活了传递,则在函数上应用3次。默认值:1
虚假控制流程
这个模式主要嵌套几层判断逻辑,一个简单的运算都会在外面包几层if-else,所以这个模式加上编译速度会慢很多因为要做几层假的逻辑包裹真正有用的代码。
另外说一下这个模式编译的时候要浪费相当长时间包哪几层不是闹得!
-mllvm -bcf:激活虚假控制流程
-mllvm -bcf_loop=3:如果激活了传递,则在函数上应用3次。默认值:1
-mllvm -bcf_prob=40:如果激活了传递,基本块将以40%的概率进行模糊处理。默认值:30
字符串混淆:
用法
-mllvm -sobf:编译时候添加选项开启字符串加密
-mllvm -seed=0xdeadbeaf:指定随机数生成器种子
效果
看个添加了-mllvm -sub -mllvm -sobf -mllvm -fla -mllvm -bcf这么一串的效果。
Ollvm反混淆
如何还原流程平坦化,三个问题需要解决:
一、找出流程里所有的相关块
二、找出各个相关块之间执行的先后顺序
三、使用跳转指令将各个相关块连接起来
可通过angr对函数生成CFG,也及是控制流程图。
ref: https://calendar.google.com/calendar/u/0/r?pli=1
常见二进制漏洞
整型溢出
整型溢出漏洞一般是 符号类型与非符号类型数值转化造成的,比如char类型的-1转换成unsigned char,就会变成255,如果没有做好相关判断,可能会造成溢出漏洞。
条件竞争
条件竞争的话,一般出现在多线程程序或者多进程操作内存变量或文件或导致被操作内存变量或文件内容造成了不可预测的状态,
Web数据库业务逻辑代码漏洞就比较多一点,在linux内核驱动中,也经常出现。
预防方案:在临界区加锁,或者让被操作的变量成为原子变量。
格式化字符串漏洞
格式化字符串漏洞是攻击者控制了格式化字符串参数,导致攻击者的输入被解析,常见拥有格式化字符串参数的函数有:
printf、scanf、sprintf、snprintf、fprintf、fscanf等等。比如说攻击者控制了printf的格式化参数,可以造成,堆栈内存数据泄露、任意地址读、任意地址写、以及crash程序等。
可以通过%p来泄露堆栈内存数据
通过%s配合地址实现任意地址数据泄露
通过%n配合地址实现任意地址任意数据写入
栈漏洞
自己以前的培训内容:
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,发生栈溢出的基本前提是
程序必须向栈上写入数据。
写入的数据大小没有被良好地控制。
例子1:
1 | |
例子2:
1 | |
回答:
堆栈溢出是函数的局部变量开辟的内存大小小于用户拷贝过来的数据大小所导致的一种漏洞,一般造成这种漏洞的函数常见的有strcpy、strncpy、strcat、memcpy、以及作者自己写的一些拷贝逻辑等。
攻击者通过该漏洞可以覆盖到函数的返回地址,那么就可以实现程序流劫持,是一种比较常见的漏洞。
在目前的编译器中,都默认开启了cannary保护来防止堆栈溢出。
ret2text攻击
控制程序执行程序本身已有的的代码 (程序.text上的代码)
一般通过堆栈溢出漏洞,劫持返回地址跳到该程序的.text端上执行代码的攻击手段,比如该程序calc函数,那么利用该手段,可以直接执行calc函数。
例子:
1 | |
ROP
ROP(Return Oriented Programming),其主要思想是在栈缓冲区溢出的基础上,通过利用程序中已有的小片段(gadgets)来改变某些寄存器或者变量的值,从而改变程序的执行流程。
gadget
这里我们将使用碎片控制指令控制想要控制的寄存器。
比如pop eax;ret;
pop eax 将栈中的可控数据弹出到eax寄存器
ret 从栈中取目标指令的地址。
数据在栈中,都是可控的,我们可以找到许多这样的碎片指令来实现控制寄存器的目的。
我们把这些碎片指令称为gadget.
Ropgadget工具使用
Ropgadget 工具 (安装pwntools时已经默认安装)
寻找gadget:
ROPgadget –binary rop –only ‘pop|ret’ | grep rdi
寻找字符串:
ROPgadget –binary rop –string ‘/bin/sh’
NX保护
NX即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行。
在历年的编译器中,编译出来的堆栈内存页权限一般都是rwx,拥有可执行权限,若攻击者在堆栈中输入shellcode,并且利用漏洞跳到堆栈中执行shellcode,这将造成程序很容易被控制。
nx保护而是将堆栈的内存页x权限给去掉,也就是没有了可执行权限,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
ret2shellcode
在nx保护没有开启的情况下,堆栈中的内存页是拥有可执行权限的,若我们劫持返回地址跳转到堆栈中执行shellcode,那么这种手段就我们可以称为ret2shellcode,当然若其他内存页也存在rwx权限,我们在目标内存中构造好shellcode,跳转过去执行也是一样的攻击手段。
常见的就是在老的编译器编译出来的程序中,往往堆栈中是拥有可执行权限的,所以如果出现了堆栈溢出漏洞,很容易造成任意代码执行。
ret2libc攻击
通过堆栈溢出漏洞,构造rop链,劫持程序流跳转到执行glibc中的执行代码的攻击手段。
比如:
控制函数的执行 libc中的函数,通常是返回至某个函数的plt处或者函数的具体位置(即函数对应的got表项的内容)。一般情况下,我们会选择执行system(“/bin/sh”),故而此时我们需要知道system函数的地址。
想要调用libc中的函数,比如system,则需要知道system的实际地址,而计算实际地址又依赖于基地址。
所以找到基地址是关键。
普遍采用的方法:
· 泄露got表中属于libc的函数地址,再通过该地址计算基地址。
实际地址 = 基地址 + 偏移
基地址 = 实际地址 – 偏移
Stack pivot
stack pivoting: 该技巧就是修改栈顶寄存器指向所能控制的内存地方,再在相应的内存地方进行 ROP。
stack pivoting情形
可以控制的栈溢出的字节数较少,难以构造较长的 ROP 链
栈地址未知,将栈劫持到已知的区域进行ROP 。
stack pivoting常见利用手段 32位
- pop esp; ret
- 修改ebp后再执行 leave; ret的gadgets
- 执行glibc中的setcontext函数中的gadgets
stack pivoting常见利用手段 64位
- pop rsp; ret
- 修改rbp后再执行 leave; ret的gadgets
- 执行glibc中的setcontext函数中的gadgets
Partial overwrite
partial overwirte也就是部分覆盖,这种方法非常常用,在栈利用和堆利用中都很常见。主要起到的作用是部分覆盖该地址内容指向我们想要的内存。
常见情形:
开启PIE保护的存在堆栈溢出留有后门的程序。
堆利用中爆破glibc中的某地址情形,比如爆破修改_IO_2_1_stdout_用于泄漏libc。
Seccomp
seccomp(全称secure computing mode)是linux kernel从2.6.23版本开始所支持的一种安全机制。
在Linux系统里,大量的系统调用(syscall)直接暴露给用户态程序。但是,并不是所有的系统调用都被需要,而且不安全的代码滥用系统调用会对系统造成安全威胁。通过seccomp,我们限制程序使用某些系统调用,这样可以减少系统的暴露面,同时是程序进入一种“安全”的状态。
ORW利用
有时候程序开启seccomp规则,导致system或者execve函数中syscall调用失败,没法获得shell,那只能构造rop,采用open,read,write函数的rop来打印flag,这种利用方法称为orw。
ret2csu攻击
在 64 位程序中,函数的前 6 个参数是通过寄存器传递的,但是大多数时候,我们很难找到每一个寄存器对应的 gadgets。 这时候,我们可以利用 x64 下的 __libc_csu_init 中的 gadgets。这个函数是用来对 libc 进行初始化操作的,而一般的程序都会调用 libc 函数,所以这个函数一定会存在。
csu是gcc编译器会为每个linux程序做初始化的一个函数,里面用于两个重要的gadget,可以轻松实现在64位程序下轻松构造包含3个参数的函数调用,利用该gadget的攻击手段叫做ret2csu。
比如在64位程序下构造 open read write 调用的rop链子,这三个函数的参数都包含了三个,使用ret2csu就十分方便构造了。
dlruntime resolve攻击
dlruntime resolve攻击是一个比较复杂的攻击方式,利用了dl根据函数名称动态查找函数地址的过程传入了伪造的link map导致根据函数名称相应动态连接库函数的攻击手段。
一般该利用方式会涉及堆栈迁移、伪造link map、got表地址偏移的计算等,64位程序构造起来比较麻烦,可能也还会涉及到ret2scu知识,32位程序有现成的工具直接生成payload。
SROP
SROP(Sigreturn Oriented Programming) 于 2014 年被 Vrije Universiteit Amsterdam 的 Erik Bosman 提出的。采用unix系统的singal机制实现rop链的构造,然而这个机制涉及的函数调用是sigreturn,系统调用号在32位程序中是72,64位程序中是15。
signal 机制
signal 机制是类 unix 系统中进程之间相互传递信息的一种方法。一般,我们也称其为软中断信号,或者软中断。
user process recevie signal -> kernel: ucontext save -> user signal handler -> kernel:ucontext restore -> process continue
signal 涉及函数如下
当由中断或异常产生时,会发出一个信号,然后会送给相关进程,此时系统切换到内核模式。
再次返回到用户模式前,内核会执行do_signal()函数,最终会调用setup_frame()函数来设置用户栈。
setup_frame函数主要工作是往用户栈中push一个保存有全部寄存器的值和其它重要信息的数据结构
(各架构各不相同),另外还会push一个signal function的返回地址——sigruturn()的地址。
srop利用方式
在堆栈中构造造sigcontext结构体,系统调用sigruturn函数,实现背景恢复。
在pwntools中,已经集成了SigreturnFrame。
x86常用条件:
int 80 ret
eax可控制
x64常用条件:
syscall ret
rax可控制
eax/ rax 控制一般我们采用read函数输入个数来进行控制。
Cannary保护
随着堆栈溢出相关CVE漏洞不断曝光,攻击者很容易通过一个堆栈溢出漏洞控制rip寄存器,cannary是一个防止堆栈溢出漏洞利用的一种保护机制,在函数调用完进入函数时,会将一个cookie值储存在堆栈底部,一般储存在rbp - 8部分(局部变量的下方),在函数返回时,会检测该值与程序中储存的cannary值是否想等,如果不相等,程序就会抛出一个异常,终止程序运行。
cannary的特性:
- 最低byte为 00
- 64位程序中,cannary值占8字节
32位程序中,cannary值占4字节
泄露cannary
若程序存在堆栈溢出漏洞,且可以覆盖到cannary部分,后续能够打印该输入内容,那么就可以泄漏cannary值。
溢出覆盖到cannary最低byte,后续泄漏7字节完毕后,还需将最低’\x00’给补回来。
PIE保护
pie保护的目的是让可执行的ELF程序加载地址进行一定的随机化,进一步提高安全性。
ALSR保护
ASLR(Address Space Layout Randomization)的目的是将程序的堆栈地址和动态链接哭加载的地址进行一定的随机化。关掉ALSR,开启了PIE保护的程序,将会受到影响,地址不会随机化。
关闭aslr: echo 0 > /proc/sys/kernel/randomize_va_space
libc函数调用过程
程序有一个程序链接表(PLT,Procedure Link Table)和存放函数地址的数据表,这个数据表一般称为全局偏移表(GOT, Global Offset Table),glibc函数初始化后调用时调用大致如下。
call printf -> printf@plt, jmp print@got -> printf@got, glibc printf
然而一般程序在刚开始运行的时候,got表中的值一般都是某个plt的地址,程序跳转到该地址后会调用_dl_runtime_resolve(link_map_obj, reloc_offset)函数进行解析。
Full RELRO保护
Full Relro保护与linux下的延迟绑定机制有关,主要作用是禁止got.plt表的写入,从而阻止攻击者通过got.plt实现劫持。
堆漏洞
堆溢出是程序开辟变量存储在堆上,且该变量的大小小于来自用户存储的数据大小所造成的一种漏洞,与栈溢出造成的原因差不多,大多数是在拷贝时计算错误或者采用比较危险的函数来进行拷贝造成的。
攻击者一般通过堆溢出结合程序实际情况,想方设法的去实现自己想要的功能,比如劫持程序流,就可以通过堆利用的各种手段去修改malloc_hook、free_hook、realloc_hook、exit_hook、以及got表等,如果程序是c++开发的,可能还有中更简单的方式,就是在堆中覆盖虚函数表地址即可。
常见的堆主要有两大漏洞,一种是Heap Overflow,另一种是UAF (Use After Free)。
堆利用思路
一般堆漏洞经常出现 堆溢出、uaf (use after free)等漏洞,结合程序逻辑采用不同利用手段实现任意内存修改为目的。当达到任意地址修改后,若我们能够劫持某些函数指针,就可以达到劫持程序流。
常见劫持程序流手段:
修改glibc中的各种hook:
__malloc_hook、__free_hook、__realloc_hook等修改elf, glibc, .so, got表
堆介绍
在程序运行过程中,对操作系统申请一个较大的内存,它允许程序申请未知大小的内存,是程序虚拟地址空间的一块连续的线性区域,它由低地址向高地址方向增长,而这块内存我们可以将他称为堆。
后续开辟一些小的内存块,采用某些内存管理机制来进行管理,一般称管理堆的那部分程序为堆管理器。
chunk结构
1 | |
prev_size: 记录的是物理相邻前一个chunk的大小(释放后),该字段也可以用来存储物理相邻的前一个 chunk 的数据 (释放前)。
size: 使低3bit值为0则当前chunk的大小.
size低三bit属性 (AMP):
NON_MAIN_ARENA: 记录当前 chunk 是否不属于主线程,1 表示不属于,0 表示属于。
IS_MAPPED: 记录当前 chunk 是否是由 mmap 分配的。
PREV_INUSE: 记录前一个 chunk 块是否被分配, 该值为0,前一个chunk被释放。
fd: 指向下一个空闲的 chunk (被释放)
bk: 指向上一个空闲的 chunk
chunk空闲的时候使用,chunk 已分配时, fd与bk是用户数据。
fd_nextsize: 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
bk_nextsize: 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
chunk 空闲的时候才使用,用于large chunk。
一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适 chunk 时挨个遍历。
top chunk
在程序第一次进行 malloc 的时候,heap 会被分为两块,一块是已开辟chunk,剩下的那块就是 top chunk。 top chunk 就是处于当前堆的物理地址最高的 chunk。它不属于任何一个 bin,在所有的 bin 都无法满足用户请求的大小时,大小小于top chunk的大小时就从top chunk中分割,将剩下的部分作为新的 top chunk。若大小大于top chunk的大小,对heap 进行扩展后再进行分配。
由主线程分配的chunk通过 sbrk 扩展 heap,而在子线程分配的chunk中通过 mmap 分配新的 heap。
Bin
bin是chunk的回收站,它用于回收各种大小的chunk,为了下次开辟内存时,可以方便的从bin中取出合适的chunk直接分配给用户。
常见的有fastbin、unsorted bin、small bin、large bin、tcache bin(glibc 2.26 >=)等等。这些bin中采用chunk的大小以及优先制度来负责把即将释放的chunk交给相应的bin来管理。
arena
arena是负责管理各种bin的机制,主线程中是main_arena,其他线程则为thread_arena,arena中包含了fastbin、unsorted bin、small bin、large bin的头节点,也记录了top chunk的地址。
而main_arena是glibc中的一个全局变量,thread_arena则不一定。
fastbin
fastbin 是一个单项链表结构,空闲的chunk中的fd代表下一个同大小空闲chunk,若fd值为0,则代表当前chunk是最后一个空闲的chunk。
一般管理大小范围: 0x01 ~ 0x80
该fastbin 管理最大堆块的大小由global_max_fast来定义,该变量是存在在glibc中的一个全局变量,若该值为0,则代表即将释放的chunk不能由fastbin来管理。
存取顺序: 先放后取
tcahcebin
glibc 2.26之后引入的机制,与fastbin类似,也是一个单向链表结构,tcache机制通过名字也可以知道,thread cache,它是用于再多线程同时管理堆块chunk时更快,在大小小于0x440以下的chunk中,由tcache bin进行管理,它有个tcache_perthread_struct在heap内存块的首地址地方(主线程),用于管理每个线程的tcache,每个tcache中对大小进行分组,每组按照0x10对齐(64),每个tcache中最多能够储存7个相同大小的chunk,超出的话就交给其他的bin进行管理。
存取顺序: 先放后取。
在2020-12月份,GNU组织向外发布了glibc 2.27跟新,加入glibc 2.29的特性,使其原来老的glibc 2.27利用方式变困难。
在chunk free的时候,会对chunk中的bk值进行检查,若该值为tcache_perthread_struct的地址,就会抛出一个异常。
绕过方法也比较简单,修改该值为非tcache_perthread_struct地址值。
unsorted bin
unsorted bin 可以视为空闲 chunk 回归其所属 bin 之前的缓冲区,在加入其他bin(small bin、large bin)之前,先将其储存至unsorted bin中,数据结构是一个双向链表结构,
储存条件:
当一个较大的 chunk 被分割成两半后,如果剩下的部分大于 MINSIZE(0x10),就会被放到 unsorted bin 中。
释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中
存取顺序: 先存先取
smallbin
small bin是管理小于0x400大小的chunk,数据结构是一个双向循环链表结构,
64位一般管理大小范围: 0x20 ~ 0x3f8
32位一般管理大小范围: 0x10 ~ 0x1f8
small bin的大小返回一般包括了fastbin管理范围,优先采用fastbin进行管理,其次再通过unsorted bin进行缓冲,若unsorted bin出现堆块分割情行,空闲的chunk符合small bin的管理范围会将其chunk交给small bin进行管理。
存取顺序: 先存先取
largebin
large bin是管理比较大的chunk,数据结构是一个双向循环链表结构,
64位一般管理大小范围: 大于等于0x400
32位一般管理大小范围: 大于等于0x200
若unsorted bin出现堆块分割情行,空闲的chunk符合large bin的管理范围会将其chunk交给largebin进行管理。
存取顺序: 先存先取
攻击手段
UAF全程是 use after free,是free掉内存之后再次使用该内存造成的一种漏洞,一般也是结合堆的一个利用手段去劫持各种hook从而打到劫持程序流的效果,比如最简单的例子:在老版本glibc 2.27中,引入有tcache机制,通过malloc开辟了一块内存后,调用free释放掉,架设程序员没有对指针进行清0,后面又再次调用free来释放该内存,就会导致tcache bin 的单向链表变成了循环链表,之后在申请一块内存,写入任意地址数据覆盖了下一个bin 的fd,就可以导致任意地址申请。
其他攻击手段:
IO_FILE利用
fastbin attack
fastbin attack,也就是利用fastbin的管理机制达到目的的一种攻击方式,可以造成开辟的堆块在任意满足fastbin条件的内存。
fastbin 是一个单向链表,若能够修改fd的值指向满足某些条件fake chunk,在后续开辟内存的时候,就可以开辟堆块到fake chunk位置。
常见能利用fastbin attack的漏洞:
heap overflow、uaf、double free。
fastbin回收fake chunk满足条件 [在free函数的检查]
1 | |
fastbin attack - 一般 fake chunk满足条件 [在malloc函数的检查]
1 | |
Fastbin attack (double free)
其次若程序中出现double free漏洞,在fastbin 中,有一个double free检查机制,但他只会检查是否是main_arena中储存的fastbin头部是否与当前释放的chunk地址相等,若相等,则抛出异常,绕过方法也比较简单,只需让mian_arena中的fastbin头部不为当前释放的chunk就行,例子如下,在后续开辟内存的时候就可以控制b的fd指向fake chunk。
1 | |
Fastbin attack (heap overflow)
若物理相邻的下一个chunk为的fastbin chunk,当前chunk存在heap overflow,覆盖数据到下一个chunk修改fd使其指向我们的fake chunk。
tcache bin attack
在glibc 2.26后续版本中增加了tcache bin机制,这一机制让堆利用变得更加简单,类似与fastbin,也是单项链表结构,利用手段更fastbin attack差不多,但没有fack chunk的检查,这意味着若劫持tcache中的fd可以实现任意地址开辟。
Unsorted bin attack
一般不会像fastbin实现向fake chunk开辟内存,unsorted bin可以实现一个向任意地址修改其内容为一个main_arena附近的地址。
基本来源
当一个较大的 chunk 被分割成两半后,如果剩下的部分大就会被放到 unsorted bin 中。
释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中。
当进行 malloc_consolidate 时,可能会把合并后的 chunk 放到 unsorted bin 中。
1 | |
ctf情形:
有时候出现随机化的8字节key值储存在某地址中,我们已知道key的地址,还有泄漏libc,我们就可以通过unsorted bin attack将key值修改为我们已知的值。
(2020祥云杯初赛 pwn1)
若有时候程序将max_global_fast设置为0,意味着不能利用fastbin attack,我们就可以通过unsorted bin attack修改max_global_fast为一个大值,后续就可以很方便的通过fastbin attack了。
1 | |
Unlink attack
unlink是一种攻击手段,与unsorted bin attack差不多,这里主要讲解glibc 2.23中的unlink,古老的unlink检查比较少,这里不讨论。unlink 简单的说就是unsorted bin在进行合并堆块的时候,需要对上一个chunk进行解链。若将当前即将解链的chunk叫做P,则解链过程如下:
P->fd->bk = P->bk
P->bk->fd = P->fd
这里的P->fd->bk与P->fd->fd的原来值就是P,若我们控制P的fd与bk,那么就可以实现P->fd->bk中写入P->bk的值。
攻击实现效果: 合并堆块、开辟内存至我们伪造的fake chunk中。
针对与古老的unlink就可以直接利用,但是目前glibc 2.23中的unlink检查如下:
1 | |
这就让P->fd->bk必须为P,P->bk->fd也为P,绕过其检查必须要伪造两个fack chunk,最简单的绕过方式就是通过unsorted bin本身特性绕过。这种方法可以实现堆块合并。
我们都知道,空闲的 unsorted bin chunk其fd与bk是main_arena附近地址,若是第一个unsorted bin chunk,
为了满足unsorted bin双向链表结构以及检查,
则一定满足P->bk->fd == P,P->fd->bk == P
若我们能够找到一块内存中储存P的地址,我们将该内存伪造成两个fake chunk,若该内存我们叫做T,则只需满足条件如下:
P->fd = T - 0x18 (fake chunk 1 -> bk,fake chunk1为T)
P->bk = T - 0x10 (fake chunk 2 -> fd, fake chunk2为T)
那么就绕过前面提到的unlink检查。
由于初始释放chunk为unsorted bin,在main_arena中会记录当前chunk的地址,而该chunk的fd与bk指向都满足unlink条件。若能够初始释放一个堆块为unsorted bin,若能够改写下一个prev_size以及inuse位,即很容易的实现堆块向前合并。
house of einherjar
glibc 2.23版本
house of einherjar 是一种堆利用技术,由 Hiroki Matsukuma 提出。该堆利用技术可以强制使得 malloc 返回一个几乎任意地址的 chunk 。其主要在于滥用 free 中的后的合并操作,从而使得尽可能避免碎片化。
free 函数中的后向合并核心操作如下
1 | |
利用原理
两个物理相邻的 chunk 会共享 prev_size字段,尤其是当低地址的 chunk 处于使用状态时,高地址的 chunk 的该字段便可以被低地址的 chunk 使用。因此,我们有希望可以通过写低地址 chunk 覆盖高地址 chunk 的 prev_size 字段。
一个 chunk PREV_INUSE 位标记了其物理相邻的低地址 chunk 的使用状态,而且该位是和 prev_size 物理相邻的。
后向合并时,新的 chunk 的位置取决于 chunk_at_offset(p, -((long) prevsize)) 。
同时控制一个 chunk prev_size 与 PREV_INUSE 字段,那么我们就可以将新的 chunk 指向几乎任何位置。(老版本libc)
glibc 2.27版本
与glibc 2.23方式差不多,只不过需要不断的释放内存构造 unsorted bin绕过unlink
检查,因为存在tcache bin,当然也可以手动构造fake chunk绕过unlink。
glibc 2.31
从glibc 2.29版本之后中多了一个检查机制,会去判断被合并的chunk size
与当前释放chunk的prev_size进行判断是否相等,如果相等才会去发生合并,
否则抛出异常。
Off by one / null
glibc 2.23
off by one是堆溢出的一个子集,表示堆溢出单字节,当然off by one也有另一个常见的攻击(off by null),原理都是一样的,溢出的这一字节条件是覆盖到了下一个chunk的size域,修改size中的P位为0,代表物理相邻的chunk处于空闲状态,结合house of einherjar攻击手段,再设置prev_size可实现堆块合并效果。再次采用fastbin attack去修改__malloc_hook为one_gadget,调用malloc函数即可get shell
glibc 2.27
采用glibc 2.27的house of enherjar方式之后实现堆块合并,再采用tcache bin attack
攻击修改__free_hook为system。释放包含有/bin/sh的堆块即可获得shell。
House of Spirit
House of Spirit 是变量覆盖和堆管理机制的组合利用,关键在于能够覆盖一个
堆指针变量,使其指向可控的区域,只要构造好数据,释放后系统会错误的
将该区域作为堆块放到相应的fast bin里面,最后再分配出来的时候,就有可能
改写我们目标区域。
House of Spirit 利用思路
(1)伪造堆块
(2)覆盖堆指针指向上一步伪造的堆块。
(3)释放堆块,将伪造的堆块释放入fastbin的单链表里面。
(4)申请堆块,将刚刚释放的堆块申请出来,最终使得可以往目标区域中写入数据,实现目的。
第一步中的伪造堆块的过程,fastbin是一个单链表结构,遵循FIFO的规则,32位系统
中fastbin的大小是在1664字节之间,64位是在32128字节之间。释放时会进行一些检查,所以需
要对伪堆块中的数据进行构造,使其顺利的释放进到fastbin里面,看堆free过程中相关的源代码。
poc
1 | |
House of Spirit 检查绕过1
1 | |
House of Spirit 检查绕过2
1 | |
其次是伪造堆块的size字段不能超过fastbin的最大值,超过的话,就不会释放到fastbin里面了。
最后是下一个堆块的大小,要大于2*SIZE_ZE小于system_mem,否则会报invalid next size的错误。
对应到伪造堆块poc来说,需要在可控区域1中伪造好size字段绕过第一个和第二个检查,
可控区域2则是伪造的是下一个堆块的size来绕过最后一个检查。
所以总的来说,house of spirit的主要意思是我们想要控制的区域控制不了,但它前面和后面都可以控制,
所以伪造好数据将它释放到fastbin里面,后面将该内存区域当做堆块申请出来,
致使该区域被当做普通的内存使用,从而目标区域就变成了可控的了。
Large bin attack
条件:
1.存在UAF或者其他漏洞能够修改同一个largbin的bk和bk_nextsize
效果
2.任意地址写堆地址。(任意地址写大数)
poc
1 | |
house of rabit
ref: https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-rabbit/
house of lore
ref: https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-lore/
house of pig
ref: https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-pig/
house of roman
这里说的是比较流行的方法,不是原作者方法。
House of Roman 这个技巧其实就是 fastbin attack 和 Unsortbin leak、partial overwrite 、结合的一个小 招式。
概括
该技术用于在未知道glibc地址的情况下,利用fastbin、unsorted bin还有partial overwrite来实现5-bit 的爆破达到获取 shell 的目的,1/16。源作者是12bit,1/4096
且仅仅只需要一个 UAF 漏洞以及能创建任意大小的 chunk 的情况下就能完成利用。
原理以及展示
将 FD 指向 malloc_hook
修正 0x71 的 fastbin list
往 malloc_hook 写入 one gadget
house of force
ref: https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-force/
IO_FILE
介绍
IO_FILE是用于描述文件的结构,其作用主要是起缓冲作用,有一定程度提升IO读写性能。在c语言标准库中,FILE结构体也就是一个IO_FILE。在标准IO中,比如stdin、stdout、stderr这些也是IO_FILE结构体,它们已定义在libc.so中,若是打开其他文件,则IO_FILE结构体在堆上。
可以在 libc.so 中找到 stdin、stdout、stderr 等变量,这些变量是指向 FILE 结构的指针,真正结构的符号是 IO_2_1_stderr_、_IO_2_1_stdout_、_IO_2_1_stdin
事实上_IO_FILE 结构外包裹着另一种结构_IO_FILE_plus,其中包含了一个重要的指针 vtable 指向了一系列函数指针。
libc2.23版本下,32 位的vtable 偏移为 0x94,64 位偏移为 0xd8
1 | |
IO_FILE结构体
1 | |
攻击
伪造vtable实现劫持
1 | |
劫持手段1-修改vtable指向的内存
1 | |
劫持手段2-修改vtable指针指向我们伪造的vtable
1 | |
FSOP
FSOP(File Stream Oriented Programming)介绍
_IO_FILE 结构会使用_chain 域相互连接形成一个链表,这个链表的头部由_IO_list_all 维护。
FSOP 的核心思想就是劫持_IO_list_all 的值来伪造链表和其中的_IO_FILE 项,但是单纯的伪造只是构造了数据还需要某种方法进行触发。FSOP 选择的触发方法是调用_IO_flush_all_lockp,这个函数会刷新_IO_list_all 链表中所有项的文件流,相当于对每个 FILE 调用 fflush,也对应着会调用_IO_FILE_plus.vtable 中的_IO_overflow。
在经典利用手段house of orange的核心就是采用fsop达到利用
FSOP - 如何触发调用?
意义是为了保证数据不丢失,因此在程序执行退出相关代码时,会去调用函数去刷新缓冲区,确保数据被保存。会_IO_flush_all_lockp调用函数的时机包括:
libc执行abort函数时。
程序执行exit函数时。
程序从main函数返回时。
FSOP - 绕过检查
1 | |
则fp->_mode <= 0 且fp->_IO_write_ptr > fp->_IO_write_base 且_IO_vtable_offset (fp) == 0,这样才能执行_IO_OVERFLOW (fp, EOF) == EOF)
house of orange
house of orange是结合堆利用与FSOP技术的一种攻击手段
利用比较特殊,首先需要目标漏洞是堆上的漏洞但是特殊之处在于程序中不存在 free 函数或其他释放堆块的函数。我们知道一般想要利用堆漏洞,需要对堆块进行 malloc 和 free 操作,但是在 House of Orange 利用中无法使用 free 函数,因此 House of Orange 核心就是通过漏洞利用获得 free 的效果。
在堆中伪造一个IO_FILE,通过FSOP达到程序流劫持。
使用堆溢出修改top chunk大小(按照内存对其), 再申请一个大小大于top chunk size 的chunk,然而old top chunk就会被free掉,申请一个large bin大小的chunk,由于large bin申请成功后fd_nextsize和bk_nextsize会指向自身地址,可以泄漏heap地址,然而,申请的位置也恰好含有以前所剩的main_arena信息,所以直接打印即可泄漏libc. 后面就通过unsorted bin attack修改IO_list_all为main_arena + 0x58, 然后根据small bin管理机制,修改main_arena + 0x58处的fake IO_FILE的chain的值指向伪造的IO_FILE,而使伪造堆块满足fp->_mode <= 0 && fp->_IO_write_ptr > fp->_IO_write_base 然后会调用vtable中的__overflow 函数,然而我们可以伪造再一个vtable,实现在调用__overflow的时候调用我们的函数,这里函数就改为system,传入参数需要在伪造的IO_FILE头部写入'/bin/sh\x00'然后在unsoretd bin被破坏之后再次申请时报错, 那触发异常就会打印错误信息,malloc_printerr是malloc中用来打印错误的函数,而 malloc_printerr其实是调用 __libc_message函数之后调用abort函数,abort`函数其中调用了_IO_flush_all_lockp, 然后根据IO_list_all中的值去遍历IO_FILE调用IO_FILE 的vtable中的 __overflow函数指针, 然后就可以调用system 传入 ‘/bin/sh\00’ get shell
IO_FILE-> chian -> malloc(0x68);
Kernel
内核提权指的是普通用户可以获取到 root 用户的权限,访问原先受限的资源。这里从两种角度来考虑如何提权
- 改变自身:通过改变自身进程的权限,使其具有 root 权限。
- 改变别人:通过影响高权限进程的执行,使其完成我们想要的功能。
ref: https://ctf-wiki.org/pwn/linux/kernel-mode/basic-knowledge/#kernel
cred
内核会通过进程的 task_struct 结构体中的 cred 指针来索引 cred 结构体,然后根据 cred 的内容来判断一个进程拥有的权限,如果 cred 结构体成员中的 uid-fsgid 都为 0,那一般就会认为进程具有 root 权限。
1 | |
因此,思路就比较直观了,我们可以通过以下方式来提权
- 直接修改 cred 结构体的内容
- 修改 task_struct 结构体中的 cred 指针指向一个满足要求的 cred
无论是哪一种方法,一般都分为两步:定位,修改。
直接改 cred
定位具体位置
我们可以首先获取到 cred 的具体地址,然后修改 cred。
定位
定位 cred 的具体地址有很多种方法,这里根据是否直接定位分为以下两种
直接定位
cred 结构体的最前面记录了各种 id 信息,对于一个普通的进程而言,uid-fsgid 都是执行进程的用户的身份。因此我们可以通过扫描内存来定位 cred。
1 | |
在实际定位的过程中,我们可能会发现很多满足要求的 cred,这主要是因为 cred 结构体可能会被拷贝、释放。一个很直观的想法是在定位的过程中,利用 usage 不为 0 来筛除掉一些 cred,但仍然会发现一些 usage 为 0 的 cred。这是因为 cred 从 usage 为 0, 到释放有一定的时间。此外,cred 是使用 rcu 延迟释放的。
间接定位
task_struct
进程的 task_struct 结构体中会存放指向 cred 的指针,因此我们可以
- 定位当前进程
task_struct结构体的地址 - 根据 cred 指针相对于 task_struct 结构体的偏移计算得出
cred指针存储的地址 - 获取
cred具体的地址
comm
comm 用来标记可执行文件的名字,位于进程的 task_struct 结构体中。我们可以发现 comm 其实在 cred 的正下方,所以我们也可以先定位 comm ,然后定位 cred 的地址。
1 | |
然而,在进程名字并不特殊的情况下,内核中可能会有多个同样的字符串,这会影响搜索的正确性与效率。因此,我们可以使用 prctl 设置进程的 comm 为一个特殊的字符串,然后再开始定位 comm。
修改
在这种方法下,我们可以直接将 cred 中的 uid-fsgid 都修改为 0。当然修改的方式有很多种,比如说
- 在我们具有任意地址读写后,可以直接修改 cred。
- 在我们可以 ROP 执行代码后,可以利用 ROP gadget 修改 cred。
间接定位
虽然我们确实想要修改 cred 的内容,但是不一定非得知道 cred 的具体位置,我们只需要能够修改 cred 即可。
UAF 使用同样堆块
如果我们在进程初始化时能控制 cred 结构体的位置,并且我们可以在初始化后修改该部分的内容,那么我们就可以很容易地达到提权的目的。这里给出一个典型的例子
- 申请一块与 cred 结构体大小一样的堆块
- 释放该堆块
- fork 出新进程,恰好使用刚刚释放的堆块
- 此时,修改 cred 结构体特定内存,从而提权
非常有意思的是,在这个过程中,我们不需要任何的信息泄露。
修改 cred 指针
定位具体位置
在这种方式下,我们需要知道 cred 指针的具体地址。
定位
直接定位
显然,cred 指针并没有什么非常特殊的地方,所以很难通过直接定位的方式定位到 cred 指针。
间接定位
task_struct
进程的 task_struct 结构体中会存放指向 cred 的指针,因此我们可以
- 定位当前进程
task_struct结构体的地址 - 根据 cred 指针相对于 task_struct 结构体的偏移计算得出
cred指针存储的地址
common
comm 用来标记可执行文件的名字,位于进程的 task_struct 结构体中。我们可以发现 comm 其实在 cred 指针的正下方,所以我们也可以先定位 comm ,然后定位 cred 指针的地址。
1 | |
然而,在进程名字并不特殊的情况下,内核中可能会有多个同样的字符串,这会影响搜索的正确性与效率。因此,我们可以使用 prctl 设置进程的 comm 为一个特殊的字符串,然后再开始定位 comm。
修改
在具体修改时,我们可以使用如下的两种方式
- 修改 cred 指针为内核镜像中已有的 init_cred 的地址。这种方法适合于我们能够直接修改 cred 指针以及知道 init_cred 地址的情况。
- 伪造一个 cred,然后修改 cred 指针指向该地址即可。这种方式比较麻烦,一般并不使用。
间接定位
commit_creds(prepare_kernel_cred(0))
我们还可以使用 commit_creds(prepare_kernel_cred(0)) 来进行提权,该方式会自动生成一个合法的 cred,并定位当前线程的 task_struct 的位置,然后修改它的 cred 为新的 cred。该方式比较适用于控制程序执行流后使用。
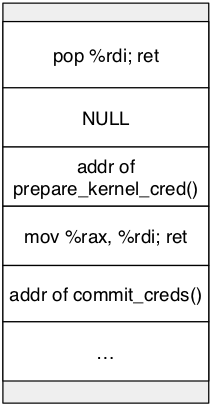
在整个过程中,我们并不知道 cred 指针的具体位置。
WEB漏洞
XSS
XSS,即跨站脚本攻击,是指攻击者利用Web服务器中的应用程序或代码漏洞,在页面中嵌入客户端脚本(通常是一段由JavaScript编写的恶意代码,少数情况下还有ActionScript、VBScript等语言),当信任此Web服务器的用户访问Web站点中含有恶意脚本代码的页面或打开收到的URL链接时,用户浏览器会自动加载并执行该恶意代码,从而达到攻击的目的。
1、反射型XSS
反射型XSS,也称为非持久性XSS,是最常见的一种XSS。
XSS代码常常出现在URL请求中,当用户访问带有XSS代码的URL请求时,服务器端接收请求并处理,然后将带有XSS代码的数据返回给浏览器,浏览器解析该段带有XSS代码的数据并执行,整个过程就像一次反射,故称为反射型XSS。
该类攻击的主要特点是它的及时性和一次性,即用户提交请求后,响应信息会立即反馈给用户。该类攻击常发生在搜索引擎、错误提示页面等对用户的输入做出直接反应的场景中。
2、存储型XSS
存储型XSS,也称为持久性XSS。
在存储型XSS中,XSS代码被存储到服务器端,因此允许用户存储数据到服务器端的Web应用程序可能存在该类型XSS漏洞。攻击者提交一段XSS代码后,服务器接收并存储,当其他用户访问包含该XSS代码的页面时,XSS代码被浏览器解析并执行。
存储型XSS攻击的特点之一是提交的恶意内容会被永久存储,因而一个单独的恶意代码就会使多个用户受害,故被称为持久性XSS,它也是跨站脚本攻击中危害最的一类。二是被存储的用户提交的恶意内容不一定被页面使用,因此存在危险的响应信息不一定被立即返回,也许在访问那些在时间上和空间上没有直接关联的页面时才会引发攻击,因此存在不确定性和更好的隐蔽性。
这类攻击的一个典型场景是留言板、博客和论坛等,当恶意用户在某论坛页面发布含有恶意的Javascript代码的留言时,论坛会将该用户的留言内容保存在数据库或文件中并作为页面内容的一部分显示出来。当其他用户查看该恶意用户的留言时,恶意用户提交的恶意代码就会在用户浏览器中解析并执行。
3、DOM型XSS
DOM (Document Objet Model)指文档对象模型。
DOM常用来表示在HTML和XML中的对象。DOM可以允许程序动态的访问和更新文档的内容、结构等。客户端JavaScript可以访问浏览器的文档对象模型。也就是说,通过JavaScript代码控制DOM节点就可以不经过服务器端的参与重构HTML页面。
该类攻击是反射型XSS的变种。它通常是由于客户端接收到的脚本代码存在逻辑错误或者使用不当导致的。比如Javascript代码不正确地使用各种DOM方法(如document.write)和Javascript内部函数(如eval函数),动态拼接HTML代码和脚本代码就容易引发DOM型的跨站脚本攻击。
因此,DOM型XSS与前面两种XSS的区别就在于DOM型XSS攻击的代码不需要与服务器端进行交互,DOM型XSS的触发基于浏览器端对DOM数据的解析来完成,也就是完全是客户端的事情。
1、检测
手工检测
手工检测重点要考虑数据输入的地方,且需要清楚输入的数据输出到什么地方。
在检测的开始,可以输入一些敏感字符,比如“<、>、()”等,提交后查看网页源代码的变化以发现输入被输出到什么地方,且可以发现相关敏感字符是否被过滤。
手工检测结果相对准确,但效率较低。
工具检测
常用工具有AVWS(Acunetix Web Vulnerability Scanner)、BurpSuite等。还有一些专门针对XSS漏洞的检测工具,如:XSSer、XSSF(跨站脚本攻击框架)、BeEF(The Browser Exploitation Framework)等。
2、防御
●使用黑名单进行
●对HTML标签或特殊字符进行过滤
●使用内容安全的CSP
●使用设计上就会自动编码的框架,如:OWASP ESAPI、React JS、JSOUP等,对于JAVA而言,可以使用ESAPI.encoder().encodeForHTML()对字符串进行HTML编码。
●对于反射型和存储型XSS,可以在数据返回给客户端浏览器时,将敏感字符进行转义,如:将单引号进行编码替换(十进制编码’、十六进制编码’、HTML编码&apos、Unicode编码\u0027等)。
●对于DOM型XSS,可以使用上下文敏感数据编码。如:在PHP中的htmlspecialchars()、htmlentities()函 数可以将一些预定义的字符转换为HTML实体,如:小于转化为<、大于转化为>、双引号转化为”、单引号转化为&apos、与转化 为&等。
●启用浏览器的HttpOnly特性可以组织客户端脚本访问cookie。如:在PHP中可以通过下面的代码设置cookie并启用HttpOnly。
1 | |
ref: https://blog.csdn.net/xcxhzjl/article/details/121404472
文件上传
漏洞原理
大部分的网站和应用系统都有上传功能,而程序员在开发文件上传功能时,并未考虑文件格式后缀的合法性校验或者是否只在前端通过js进行后缀检验。
这时攻击者可以上传一个与网站脚本语言相对应的恶意代码动态脚本,例如(jsp、asp、php、aspx文件后缀)到服务器上,从而访问这些恶意脚本中包含的恶意代码,进行动态解析最终达到执行恶意代码的效果,进一步影响服务器安全。
文件上传漏洞是指用户上传了一个可执行的脚本文件,并通过此脚本文件获得了执行服务器端命令的能力。一般都是指“上传Web脚本能够被服务器解析”的问题。
漏洞危害
可能会导致用户信息泄露,被钓鱼,甚至使攻击者可以直接上传WebShell到服务器,进而得到自己想要的信息和权限。最终达到对数据库执行、服务器文件管理、服务器命令执行等恶意操作,甚至完全控制服务器系统。
webshell:运行在web应用之上的远程控制程序 。 webshell分为大马、小马等。功能简易的webshell称为小马,拥有较完整功能的webshell,称为大马。
一句话木马:
1 | |
漏洞利用
文件上传漏洞利用条件:
(1)能够成功上传木马。
(2)上传的木马能够被web容器解析执行,所以上传路径要在web容器覆盖范围内。
(3)用户能够访问上传的木马,所以得知道上传的木马准确路径。
ref:https://blog.csdn.net/ma963852/article/details/123085437
SSRF
SSRF (Server-Side Request Forgery,服务器端请求伪造) 是一种由攻击者构造请求,由服务端发起请求的安全漏洞,一般情况下,SSRF攻击的目标是外网无法访问的内网系统,也正因为请求是由服务端发起的,所以服务端能请求到与自身相连而与外网隔绝的内部系统。也就是说可以利用一个网络请求的服务,当作跳板进行攻击。
攻击者利用了可访问Web服务器(A)的特定功能 构造恶意payload;攻击者在访问A时,利用A的特定功能构造特殊payload,由A发起对内部网络中系统B(内网隔离,外部不可访问)的请求,从而获取敏感信息。此时A被作为中间人(跳板)进行利用。
SSRF漏洞的形成大多是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤和限制。 例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片,下载等,利用的就是服务端请求伪造,SSRF利用存在缺陷的WEB应用作为代理 攻击远程 和 本地的服务器。
2、漏洞成因
1.服务端提供了从其他服务器应用获取数据的功能
2.没有对目标地址做过滤与限制
比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载文件等等
漏洞产生与危害
在PHP中的curl(),file_get_contents(),fsockopen()等函数是几个主要产生ssrf漏洞的函数
ref :https://blog.csdn.net/nobugnomoney/article/details/123953973
CSRF
一、介绍
CSRF是指利用受害者尚未失效的身份认证信息( cookie、会话等信息),诱骗其点击恶意链接或者访问包含攻击代码的页面,在受害人不知情的情况下以受害者的身份向服务器发送请求,从而完成非法操作(如转账、改密、信息修改等操作)。
CSRF与XSS最大的区别就在于,CSRF并没有盗取cookie而是直接利用
ref :https://blog.csdn.net/weixin_39861994/article/details/121035470
二、CSRF类型:
get请求型CSRF
只需要构造URL,然后诱导受害者访问利用。
POST请求型CSRF
构造自动提交的表单,诱导受惠者访问或者点击
三、CSRF漏洞危害:
以受害者的名义发送邮件、发消息、盗取受害者的账号,甚至购买商品、虚拟货币转账、修改受害者的网络配置(比如修改路由器DNS、重置路由器密码)等等操作。造成的问题包括:个人隐私的泄露、机密资料的泄露、用户甚至企业的财产安全;
一句话概括CSRF的危害:盗用受害者的身份,受害者能做什么,攻击者就能以受害者的身份做什么。
四、CSRF漏洞利用思路:
寻找有权限进行增删改查操作的功能点:比如修改密码、修改个人信息等等,通过burp构造HTML,修改HTML表单中某些参数,使用浏览器打开该HTML,点击提交表单后查看响应结果,看该操作是否成功执行。
五、CSRF漏洞修复建议
token随机值防御
在请求地址中添加token并验证;
CSRF之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存储在cookie中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的cookie来通过验证。
要低于CSRF,关键在于在请求中放入和黑客所不能伪造的信息,并且该信息不存在于cookie中。可以在http请求中以参数的形式加入一个随机产生的token,并且在服务器端建立一个拦截器来验证这个token值,如果请求中没有token值或者token不正确,则可以认为可能是CSRF攻击而拒绝请求。
- referer值校验
增加HTTP referer的校验:
根据http协议,在http头部中有一个字段叫referer,它记录了该http请求的来源地址。如果referer记录的不是同一个浏览器的请求,那么久可能是攻击者伪造的恶意链接,可以根据此方法来防范CSRF攻击
Sql注入
结构化查询语言(Structured Query Language,简称SQL)是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系型数据库。SQL注入漏洞主要形成的原因是Web应用程序对用户的输入没有做严格的判断,导致用户可用将非法的SQL语句拼接到正常的语句中,被当作SQL语句的一部分执行。
二、SQL注入分类
①按照提交的数据类型有:数字型、字符型和搜索型;
③按照执行效果有:基于布尔的盲注、基于时间的盲注、基于报错注入、联合查询注入等;
SQL注入漏洞产生原因及危害
SQL注入漏洞是指攻击者通过浏览器或者其他客户端将恶意SQL语句插入到网站参数中,而网站应用程序未对其进行过滤,将恶意SQL语句带入数据库使恶意SQL语句得以执行,从而使攻击者通过数据库获取敏感信息或者执行其他恶意操作。
SQL注入漏洞可能会造成服务器的数据库信息泄露、数据被窃取、网页被篡改等!!
web页面源代码对用户提交的参数没有做出任何过滤限制,直接扔到SQL语句中去执行,导致特殊字符改变了SQL语句原来的功能和逻辑。黑客利用此漏洞执行恶意的SQL语句,如查询数据、下载数据,写webshell、执行系统命令以此来绕过登录权限限制等。
注入条件
SQL 注入需要满足以下两个条件:
1.参数可控:从前端传给后端的参数内容是用户可以控制的
2.参数带入数据库查询:传入的参数拼接到 SQL 语句,且带入数据库查询。
盲注
1.布尔盲注
没有返回SQL执行的错误信息
错误与正确的输入,返回的结果只有两种
使用布尔类型盲注的操作步骤:
- 构造目标查询语句
- 选择拼接方式
- 构造判断表达式
- 提取数据长度
- 提取数据内容
2.时间盲注
页面上没有显示位和SQL语句执行的错误信息,正确执行和错误执行的返回界面一样,此时需要使用时间类型的盲注。
时间型盲注与布尔型盲注的语句构造过程类似,通常在布尔型盲注表达式的基础上使用IF语句加入延时语句来构造,由于时间型盲注耗时较大,通常利用脚本工具来执行,在手工利用的过程中较少使用。
时间类型盲注的注意事项
- 通常使用sleep()等专用的延时函数来进行时间盲注,特殊情况下也可以使用某些耗时较高的操作代替这些函数。
- 为了提高效率,通常在表达式判断为真时执行延时语句。
- 时间盲注语句拼接时无特殊要求,保证语法正确即可。
SQL注入绕过
空格过滤绕过
/**/绕过
MySQL数据库中可以用/**/(注释符)来代替空格,将空格用注释符代替后,SQL语句就可以正常运行。例如:
http://192.168.40.1/index.php?id=1/**
/1=2/**
/union/**
/select/**/1,2,database()
制表符绕过
在MySQL数据库中可以用制表符来代替空格,将空格用制表符代替后,SQL语句就可以正常运行。制表符是不可见的,在URL传输中需要编码,其URL编码为%09。例如:
http://192.168.40.1/index.php?id=1%091=2%09union%09select%091,2,database()
换行符绕过
MySQL数据库支持换行执行SQL语句,可以利用换行符代替空格,换行符也是不可见字符,其URL编码为%0a。
http://192.168.40.1/index.php?id=1%0a1=2%0aunion%0aselect%0a1,2,database()
大小写绕过
根据应用程序的过滤规则中可能存在过滤不完整或者之过滤小写或者大写的情况,此时我们就可以利用大小写混写。
http://192.168.40.1/index.php?id=1 and 1=2 union seLeCt 1,2,database()
双写关键字绕过
测试代码如下:
http://192.168.40.1/index.php?id=1 and 1=2 union seselectlect
1,2,database()
等价函数字符替换绕过
1.用like或in代替=
http://192.168.40.1/index.php?id=1 and 1 like 1
2.等价函数
sleep函数可以用benchmark函数代替。 ascii函数可以用hex、bin函数代替
ref:https://blog.csdn.net/m0_56822024/article/details/125685506
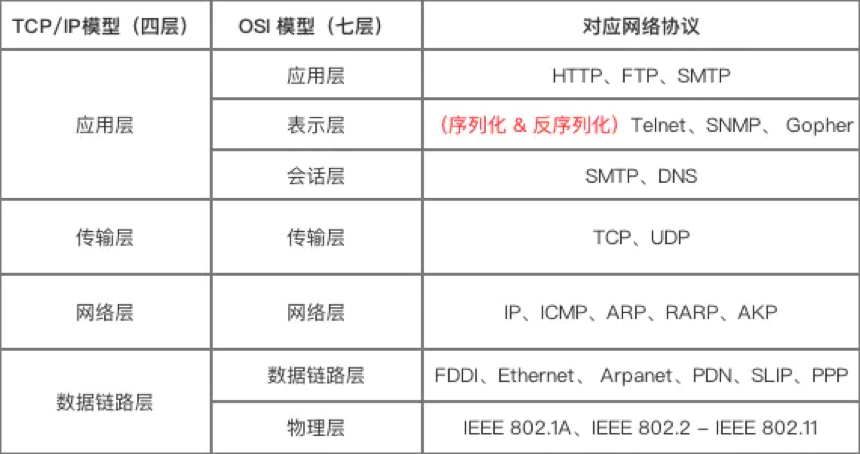
协议
TCP
TCP协议段格式
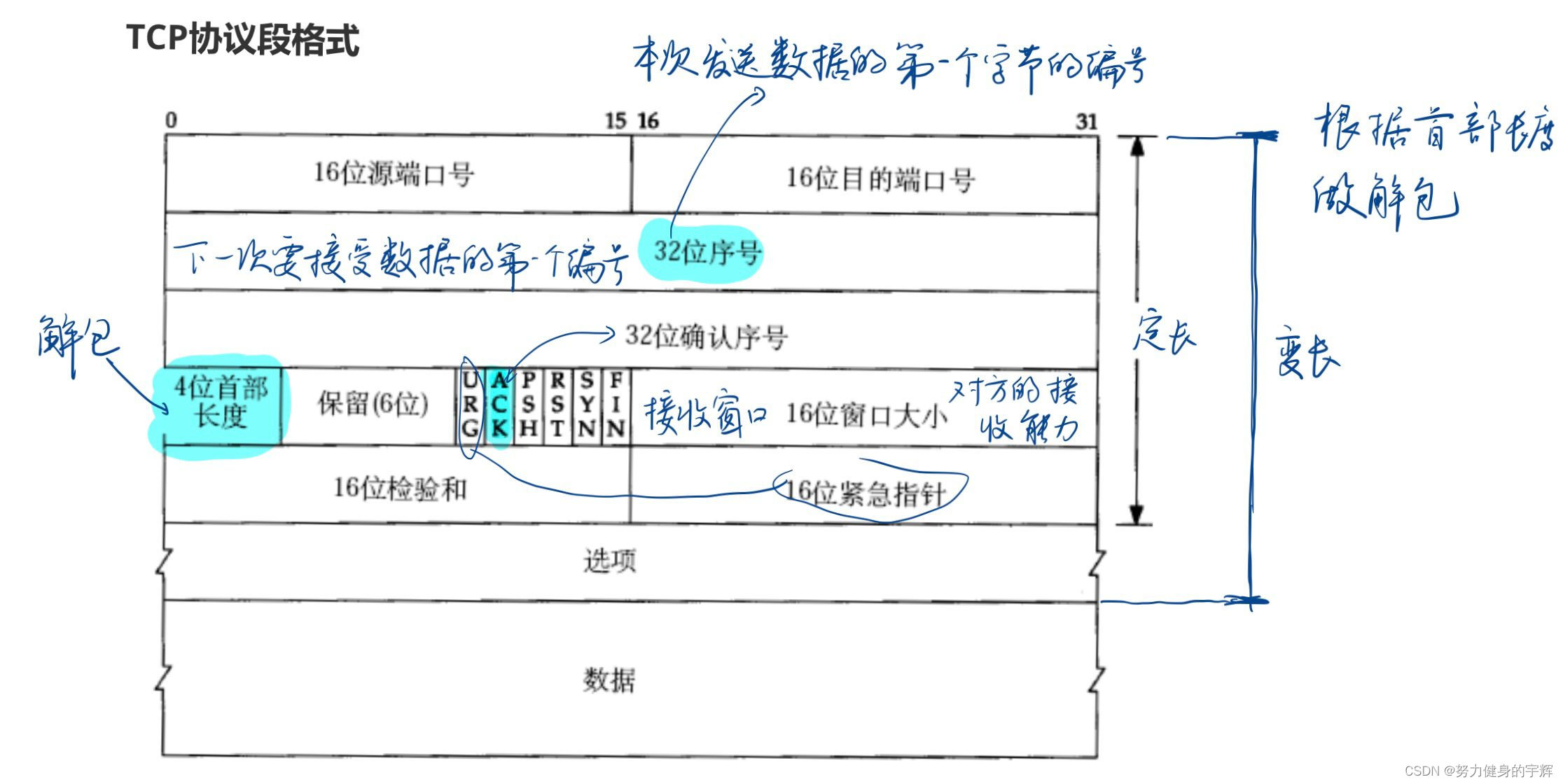
源/目的端口号:表示数据从哪个进程来,到那个进程去。
源端口号表示报文的发送端口,源端口号和源IP地址组合起来可以表示报文的发送地址。
目的端口表示报文的接收端口,目的端口和目的IP地址组合起来可以表示报文的接收地址。
TCP协议就是根据IP协议的基础上传输的,TCP报文中的源端口号+源IP,与TCP报文中的目的端口号+目的IP一起,组合起来唯一性的确定一条TCP连接。
序号(Sequence Number):TCP传输过程中,在发送端出的字节流中,传输报文中的数据部分的每一个字节都有它的编号。序号(Sequence
Number)占32位,发起方发送数据时,都需要标记序号。
在数据传输过程中,TCP协议通过序号(Sequence
Number)对上层提供有序的数据流。发送端可以用序号来跟踪发送的数据量;接收端可以用序号识别出重复接收到的TCP包,从而丢弃重复包;对于乱序的数据包,接收端也可以依靠序号对其进行排序。
序号会根据SYN是否为1,表示不同的意思:
当SYN为1时,当前为建立连接阶段;
当SYN为0是,数据传输正式开始。
确认序号(Acknowledgment Number):确认序号标识了报文接收端期望接收的字节序列。如果设置了ACK控制位,确认序号的值表示一个准备接收的包的序列号,注意,它所指向的是准备接收的包,也就是下一个期望接收的包的序列号。
4位TCP报头长度:表示TCP头部有多少个32位bit(4字节);所以TCP头部最大长度为 15 * 4 = 60字节。
6位标志位:
URG:紧急指针是否有效;
ACK:确认号是否有效,ACK置 1 ,代表起到了确认作用,需要填写确认序列号(下一次期望收到第一个字节的序列号);
PSH:提示接收端应用程序立刻从TCP缓冲区把数据读走;
RST:对方要求重新建立连接,我们把携带RST标识的称为复位报文段;
SYN:请求建立连接,我们把携带SYN标识的成为同步报文段;
FIN:通知对方,本端要关闭了,我们称携带FIN标识的为结束报文段。
窗口大小:长度为16位,共2个字节。此字段用来进行流量控制。流量控制的单位为字节数,这个值是本端期望一次接收的字节数。
16位校验和:发送端填充,CRC校验。接收端校验不通过,则认为数据有问题,此处的检验和不光包含TCP首部,也包含TCP数据部分。
16位紧急指针:标识那部分数据是紧急数据。
TCP原理
TCP对数据传输提供的管控机制,主要体现在两个方面:安全、效率。
这些机制和多线程的设计原则类似:保证数据传输的安全前提下,尽可能地提高传续效率。
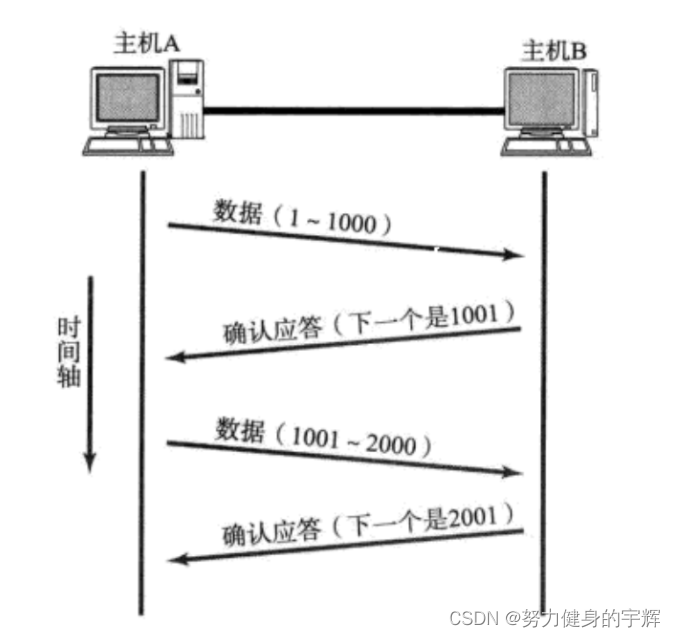
确认应答机制
TCP将每个字节的数据进行了编号,即序列号。
每一个ACK都带有对应的确认序列号,意思是告诉发送者,我已经收到了那些数据,下一次你从哪里开始给我发。
超时重传机制
主机A给主机B发送了数据之后,可能会因为网络拥堵等原因,数据无法发送到B,如果A在一个特定的时间间隔内没有收到B发来的确认应答,就会重新发送。
当然,A没有收到确认应答,也可能是ACK丢了。因此,主机B会收到很多重复数据,可以利用序列号做到去重的效果。
那么超时时间如何确定?
最理想的情况下,找到一个最小的时间,保证 “确认应答一定能在这个时间内返回”。
但是这个时间的长短,随着网络环境的不同,是有差异的。
如果超时时间设的太长,会影响整体的重传效率;
如果超时时间设的太短,有可能会频繁发送重复的包
TCP为了保证无论在任何环境下都能比较高效地通信,因此会动态计算这个最大超时时间。
Linux中(BSD Unix和Windows也是如此),超时以500ms为一个单位进行控制,每次判定
超时重发的超时时间都是500ms的整数倍。
如果重发一次之后,仍然得不到应答,等待 2500ms后再进行重传。如果仍然得不到应答,等待 4500ms 进行重传。依次类推,以指数形式递增。
累计到一定的重传次数,TCP认为网络或者对端主机出现异常,强制关闭连接。
连接管理机制
在正常情况下,TCP要经过三次握手建立连接,四次挥手断开连接
三次握手:
第一次握手:客户端进入SYN_SENT状态,发送一个SYN帧来主动打开传输通道,该帧的SYN标志位被设置为1,同时会带上Client分配好的SN序列号,该SN是根据时间产生的一个随机值。
第二次握手:服务端在收到SYN帧之后,会进入SYN_RCVD状态,同时返回SYN+ACK帧给客户端,主要目的在于通知客户端,服务端已经收到SYN消息,现在需要进行确认。
服务端发出的SYN+ACK帧的ACK标志位被设置为1,其确认序号ASN值被设置为客户端的SN+1;SYN+ACK帧的SYN标志位被设置为1,SN值为服务端生成的SN序号。
第三次握手:客户端在收到服务端的第二次握手的SYN+ACK确认帧之后,首先将自己的状态会从SYN_SENT变成ESTABLISHED,表示自己方向的连接通道已经建立成功,客户端可以发送数据给服务端了。然后,客户端发ACK帧给服务端,该ACK帧的ACK标志位被设置为1,其确认序号ASN值被设置为服务端的SN序列号+1。
服务端收到客户端的ACK之后,会从SYN_RCVD状态变成ESTABLISHED状态,至此,TCP全双工连接建立完成。
四次挥手:
第一次挥手:主动断开方向对方发送一个FIN结束请求报文,此报文的FIN位被设置为1,发送完成后,主动断开方进入FIN_WAIT_1状态,这表示主动断开方没有业务数据要发送给对方,准备关闭SOCKET连接了。
第二次挥手:正常情况下,在收到了主动断开方发送的FIN断开请求报文后,被动断开方会发送一个ACK响应报文,之后,被动断开方就进入了CLOSE-WAIT(关闭等待)状态,TCP协议服务会通知高层的应用进程,对方向本地方向的连接已经关闭,对方已经没有数据要发送了,若本地还要发送数据给对方,对方依然会接受。被动断开方的CLOSE-WAIT(关闭等待)还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
第三次挥手:在发送完成ACK报文后,被动断开方还可以继续完成业务数据的发送,待剩余数据发送完成后,或者CLOSE-WAIT(关闭等待)截止后,被动断开方会向主动断开方发送一个FIN+ACK结束响应报文,表示被动断开方的数据都发送完了,然后,被动断开方进入LAST_ACK状态。
第四次挥手:主动断开方收在到FIN+ACK断开响应报文后,还需要进行最后的确认,向被动断开方发送一个ACK确认报文,然后,自己就进入TIME_WAIT状态,等待超时后最终关闭连接。处于TIME_WAIT状态的主动断开方,在等待完成2MSL的时间后,如果期间没有收到其他报文,则证明对方已正常关闭,主动断开方的连接最终关闭。
被动断开方在收到主动断开方的最后的ACK报文以后,最终关闭了连接。
为什么TIME_WAIT的时间是2MSL呢?
MSL是TCP报文的最大生存时间,因此TIME_WAIT持续存在2MSL的话就能保证在两个传输方向上的尚未被接收或迟到的报文段都已经消失(否则服务器立刻重启,可能会收到来自上一个进程的迟到的数据,但是这种数据很可能是错误的);
同时也是在理论上保证最后一个报文可靠到达(假设最后一个ACK丢失,那么服务器会再重发一个FIN。这时虽然客户端的进程不在了,但是TCP连接还在,仍然可以重发LAST_ACK)。
TCP状态转换汇总:
滑动窗口
刚才我们讨论了确认应答策略,对每一个发送的数据段,都要给一个ACK确认应答。收到ACK后再发送下一个数据段。这样做有一个比较大的缺点,就是性能较差。尤其是数据往返的时间较长的时候。
既然这样一发一收的方式性能较低,那么我们一次发送多条数据,就可以大大的提高性能(其实是将多个段的等待时间重叠在一起了)。
窗口大小指的是无需等待确认应答而可以继续发送数据的最大值。上图的窗口大小就是4000个字节(四个段)。
发送前四个段的时候,不需要等待任何ACK,直接发送;
收到第一个ACK后,滑动窗口向后移动,继续发送第五个段的数据;依次类推;
操作系统内核为了维护这个滑动窗口,需要开辟 发送缓冲区 来记录当前还有哪些数据没有应答;只有确认应答过的数据,才能从缓冲区删掉;
窗口越大,则网络的吞吐率就越高
如果出现丢包,如何进行重传?
情况一:数据包已经抵达,ACK被丢了
这种情况下,部分ACK丢了并不要紧,因为可以通过后续的ACK进行确认
情况二:数据包就直接丢了
当某一段报文段丢失之后,发送端会一直收到 1001 这样的ACK,就像是在提醒发送端 “我想要的是 1001” 一样;
如果发送端主机连续三次收到了同样一个 “1001” 这样的应答,就会将对应的数据 1001 - 2000 重新发送;
这个时候接收端收到了 1001 之后,再次返回的ACK就是7001了(因为2001 - 7000)接收端其实之前就已经收到了,被放到了接收端操作系统内核的接收缓冲区中
流量控制
接收端处理数据的速度是有限的。如果发送端发的太快,导致接收端的缓冲区被打满,这个时候如果发送端继续发送,就会造成丢包,继而引起丢包重传等等一系列连锁反应。
因此TCP支持根据接收端的处理能力,来决定发送端的发送速度。这个机制就叫做流量控制(Flow Control)。
ref:https://blog.csdn.net/m0_50370214/article/details/124888963
UDP
英语:User Datagram Protocol,缩写为UDP
一种用户数据报协议,又称用户数据报文协议
是一个简单的面向数据报的传输层协议,正式规范为RFC 768
用户数据协议、非连接协议
二、为什么不可靠
它一旦把应用程序网络层的数据发送出去,就不保留数据备份
UDP在IP数据报的头部仅仅加入了复用和数据校验(字段)
发送端生产数据,接收端从网络抓取数据
结构简单、无校验、速度快、容易丢包、可广播
三、UDP能做什么
DNS、TFTP、SNMP
视频、音频、普通数据(无关紧要数据)
四、UDP包最大长度

16位->2字节 存储长度信息
2^16-1=64K-1=65536-1=65535
自身协议占用:32位+32位=64位=8字节
65535-8=65507 byte
KCP
KCP是一个快速可靠协议,能以比 TCP浪费10%-20%的带宽的代价,换取平均延迟降低 30%-40%,且最大延迟降低三倍的传输效果。纯算法实现,并不负责底层协议(如UDP)的收发,需要使用者自己定义下层数据包的发送方式,以 callback的方式提供给 KCP。 连时钟都需要外部传递进来,内部不会有任何一次系统调用。
技术特性
TCP是为流量设计的(每秒内可以传输多少KB的数据),讲究的是充分利用带宽。而 KCP是为流速设计的(单个数据包从一端发送到一端需要多少时间),以10%-20%带宽浪费的代价换取了比 TCP快30%-40%的传输速度。TCP信道是一条流速很慢,但每秒流量很大的大运河,而KCP是水流湍急的小激流。KCP有正常模式和快速模式两种,通过以下策略达到提高流速的结果:
RTO翻倍vs不翻倍:
TCP超时计算是RTOx2,这样连续丢三次包就变成RTOx8了,十分恐怖,而KCP启动快速模式后不x2,只是x1.5(实验证明1.5这个值相对比较好),提高了传输速度。
选择性重传 vs 全部重传:
TCP丢包时会全部重传从丢的那个包开始以后的数据,KCP是选择性重传,只重传真正丢失的数据包。
快速重传:
发送端发送了1,2,3,4,5几个包,然后收到远端的ACK: 1, 3, 4, 5,当收到ACK3时,KCP知道2被跳过1次,收到ACK4时,知道2被跳过了2次,此时可以认为2号丢失,不用等超时,直接重传2号包,大大改善了丢包时的传输速度。
延迟ACK vs 非延迟ACK:
TCP为了充分利用带宽,延迟发送ACK(NODELAY都没用),这样超时计算会算出较大 RTT时间,延长了丢包时的判断过程。KCP的ACK是否延迟发送可以调节。
UNA vs ACK+UNA:
ARQ模型响应有两种,UNA(此编号前所有包已收到,如TCP)和ACK(该编号包已收到),光用UNA将导致全部重传,光用ACK则丢失成本太高,以往协议都是二选其一,而 KCP协议中,除去单独的 ACK包外,所有包都有UNA信息。
非退让流控:
KCP正常模式同TCP一样使用公平退让法则,即发送窗口大小由:发送缓存大小、接收端剩余接收缓存大小、丢包退让及慢启动这四要素决定。但传送及时性要求很高的小数据时,可选择通过配置跳过后两步,仅用前两项来控制发送频率。以牺牲部分公平性及带宽利用率之代价,换取了开着BT都能流畅传输的效果。
协议定义
3.1 kcp协议
1 | |
3.2 enet协议对比
1 | |
流程图
4.1 发送流程

4.2 接收流程

ref:https://www.jianshu.com/p/28d4b02e7eb4
HTTP
http协议简介
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是应用层协议。HTTP是万维网的数据通信的基础。
http协议概述
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如”HTTP/1.1 200 OK”,以及返回的内容,如请求的文件、错误消息、或者其它信息。
http工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
HTTP 请求和响应的步骤
客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.baidu.com。
发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
5 URL
超文本传输协议(HTTP)的统一资源定位符将从因特网获取信息的五个基本元素包括在一个简单的地址中:
(1)传送协议。
(2)层级URL标记符号(为[//],固定不变)
(3)访问资源需要的凭证信息(可省略)
(4)服务器。(通常为域名,有时为IP地址)
(5)端口号。(以数字方式表示,若为HTTP的默认值“:80”可省略)
(6)路径。(以“/”字符区别路径中的每一个目录名称)
(7)查询。(GET模式的请求参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题)
以http://www.baidu.com:80/news/index.html?id=250&page=1 为例, 其中:
http : 是协议;
www.baidu.com: 是服务器(域名);
80:是服务器上的网络端口号;
/news/index.html,是路径;
?id=250&page=1,是查询(携带参数)。
以?区别路径和参数,参数使用键值对方式name=’zs’&age=10,每个键值对使用&符号链接。
HTTP 请求格式
提示: 回车符 \r 换行符 \n
请求首行分析:
请求方式: GET 和 POST 方式
GET请求:地址栏访问、超链接访问都是get请求方式,get请求方式不安全,地址栏大小有限。
POST请求:内容在请求体中,数据安全,理论上内容可以无限。
请求地址:访问服务器的哪个目录。
请求协议: HTTP版本有1.0和1.1两个版本, 1.0版本建立连接后立即断开,下次访 问需要再次建立连接, 1.1版本 建立连接后可以不用断开,直到不发送信息后 才断开节约了资源;
请求头分析
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8
表示客户端可以接受的内容类型, 多个值使用;分号隔开 q=0.9 表示权重优先级,*/*表示可以接受任意类型内容;
2、Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
表示客户端可以接受的语言
3、User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64;
浏览器信息,例如使用的是网井的内核, windows64位系统;
4、Accept-Encoding: gzip, deflate–>>支持的压缩格式
5、Host: localhost:8888====>访问地址
6、Connection: keep-alive —>>保持连接 和HTTP1.1版本有关,默认保持3s
7、Content-Type: application/x-www-form-urlencoded
表单提交时才有可能出现,表示表单的数据类型,使用url编码,url编码 % 16位数
8、Content-Length: 7 —>post请求 请求体长度
9、Upgrade-Insecure-Requests: 1–>>告诉服务器,浏览器可以处理https协议、
请求空行分析:
就是一个分隔符,用来区分请求头和请求体的;
请求体分析:
只有POST请求才有请求体,
因此 POST请求 请求体中存放的是表单提交的键值对。
name=’zs’&age=10
HTTP响应格式
响应首行(状态行)分析:
HTTP/1.1 200 OK
包含 协议–>>HTTP/1.1, 响应码(状态码)—>>200 , 状态码描述—>>OK
状态码
200: 服务器很好的处理了客户端的请求,一切 OK
301:表示永久性重定向
302:表示临时性重定向
304:通常表示资源文件在服务器没有更改,而浏览器端又有缓存,这时候回送 304 状体码通知浏览器拿本地的缓存显示
404:表示客户端访问的资源路径有问题或者资源问题不存在
500:表示服务器出现了 异常.
响应头部分析
server: Apache-Coyote/1.1—>> 服务器版本号
Set-Cookie: JSESSIONID=ECA8005D1235BBB6B9CFCC338A8206FD;
Path=/03test; HttpOnly学cookie时在讲
Content-Type: text/html;charset=ISO-8859-1响应字符集,告诉浏览器以什么样的字符集解码;
Content-Length: 265 响应体长度
Date: Fri, 23 Jun 2017 13:45:01 GMT 发送日期 少8个小时;
Expires: -1、Cache-control:no-cache、Pragma:no-cache 三个响应头一起使用, 表示禁止浏览器缓存当前页面. 每个浏览器厂商对认识的禁止头不同因此三 个一起使用。
ref:https://blog.csdn.net/NONUONODAI/article/details/89465789
SSL
SSL(Secure Socket Layer)安全套接层是Netscape公司率先采用的网络安全协议
SSL工作大致可以分为两个阶段
1.第一阶段: Handshake phase(握手阶段)
协商加密算法
认证服务器
建立用于加密和MAC(Message Authentication Code)的会话密钥
2.第二阶段: Secure data transfer phase(安全数据传输阶段)
在已经建立的SSL数据通道里安全的传输数据
SSL协议提供的服务:
1)认证用户和服务器,确保数据发送到正确的 客户机和服务器
2)加密数据以防止数据中途被窃取
3)维护数据的完整性,确保数据在传输过程中不被改变。
当你在浏览器的地址栏上输入https开头的网址后,浏览器和服务器之间会在接下来的几百毫秒内进行大量的通信:
认证服务器:浏览器内置一个受信任的CA机构列表,并保存了这些CA机构的证书。第一阶段服务器会提供经CA机构认证颁发的服务器证书,如果认证该服务器证书的CA机构,存在于浏览器的受信任CA机构列表中,并且服务器证书中的信息与当前正在访问的网站(域名等)一致,那么浏览器就认为服务端是可信的,并从服务器证书中取得服务器公钥,用于后续流程。否则,浏览器将提示用户,根据用户的选择,决定是否继续。当然,我们可以管理这个受信任CA机构列表,添加我们想要信任的CA机构,或者移除我们不信任的CA机构。
SSL原理
在用SSL进行通信之前,首先要使用SSL的Handshake协议在通信两端握手,协商数据传输中要用到的相关安全参数(如加密算法、共享密钥、产生密钥所要的材料等),并对对端的身份进行验证。
SSL第一阶段
客户端首先发送ClientHello消息到服务端,服务端收到ClientHello消息后,再发送ServerHello消息回应客户端。

ClientHello
客户端浏览器向服务器端发送如下信息:
Version 版本号(客户端支持的SSL /TLS协议的版本号。)
Random 客户端产生的#随机数#
Session id 会话ID
Cipher Suite(密钥算法套件):加密套件里面包含三部分:
1、加密算法;
2、完整性校验算法(MD5,哈希算法);
3:密钥协商算法;主要看客户端和服务端支持哪一个算法,客户端会把自己支持的加密算法发送给服务端。
Compression Methods(压缩算法)
预留
ServerHello
服务器端向客户端发送如下信息:
服务器把自己支持的版本列出来,然后和客户端进行比较,拿出客户端支持的最新版本
服务器端产生#随机数#
服务端也列出加密套件,协商后使用统一的 加密套件
客户端产生的会话ID写进服务器里面
如果支持客户端的压缩算法,则使用
扩展包
在此阶段之后通信双方分别确定了:
1、SSL的版本;2、加密套件;3、压缩算法;4、俩个随机数
SSL第二阶段
服务器向客户端发送消息,本阶段服务器是唯一发送方,客户端是唯一接收方。
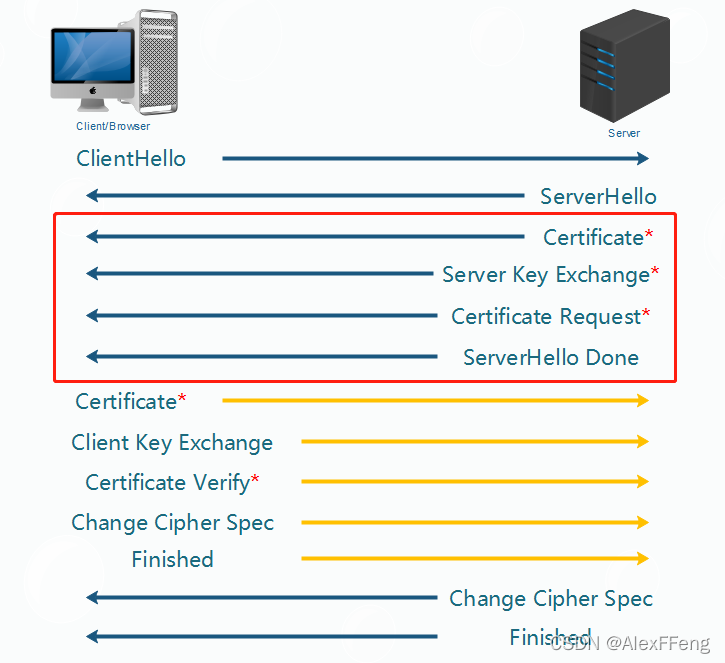
本阶段共有四个消息,如下:
证书:服务器将数字证书和到根CA整个链发给客户端,使客户端能用服务器证书中的服务器公钥认证服务器。
服务器密钥交换(可选):这里视密钥交换算法而定。
证书请求:服务端可能会要求客户自身进行验证。
服务器握手完成:第二阶段的结束,第三阶段开始的信号
Certificate(可选)——第一次建立必须要有证书
一般情况下,除了会话恢复时不需要发送该消息,在SSL握手的全过程中都需要该消息。消息中包含一个X.509证书,证书中包含公钥,发给客户端用来验证签名或者在密钥交换时给消息加密。
这一步是服务端将自己的证书下发给客户端,让客户端验证自己的身份,客户端验证通过后取出证书中的公钥,以便后面的使用。
Server Key Exchange(可选)
根据之前的client hello消息中的cipther suite信息决定了,密钥交换的方法(例如RSA和DH),因此在此消息中便会完成密钥交换所需的一系列参数。
Certificate Request(可选)——可以是单向身份认证,也可以是双向
这一步是可选的,在安全性要求高的场合可以看到;服务端发送Certificate Request消息,请求客户端发送他自己的证书来进行验证。该消息中包含服务器端支持的证书类型(RSA、DSA、ECDSA),和服务器所信任的所有证书的发行机构的CA列表,客户端会用这些信息来筛选证书。
ServerHello Done
表示服务器已将所有的信息发送完毕,等待客户端发送消息
SSL第三阶段
客户端收到服务器发送的一系列消息并解析后,将本端相应的消息发送给服务器。
客户机启动SSL握手第3阶段,是本阶段所有消息的唯一发送方,服务器是所有消息的唯一接收方。该阶段分为3步:
证书(可选):为了对服务器证明自身,客户要发送一个证书信息,这是可选的,在IIS中可以配置强制客户端证书认证。
客户机密钥交换(Pre-master-secret):这里客户端将预备主密钥发送给服务端,注意这里会使用服务端的公钥进行加密。
证书验证(可选):对从第一条消息以来的所有握手消息进行签名。
Certificate(可选)
如果在第二阶段服务器要求客户端发送证书,客户端便会发送自己的证书,服务器端之前在发送的Certificate Request消息中包含了服务器所支持的证书类型和CA列表,客户端会在证书中找到满足要求的一个发送给服务器。若客户端没有证书,则会发送一个no_certificate警告。
Client Key Exchange
根据之前从服务端收到的随机数,按照不同的密钥交换算法,算出一个Pre-master,发送给服务器,服务器收到pre-master,算出一个main-master。而客户端也能通过Pre-master自己算出一个main-master。如此一来,双方就算出了对称密钥。
如果是RSA算法,会生成一个48位的随机数,然后用server的公钥加密后放入报文中;如果是DH算法,发送的就是客户端的DH参数,之后客户端和服务端根据DH算法,计算出相同的Pre-master secret。
本消息在发送过程中,使用了服务器的公钥加密,服务器在收到后需要用服务器的私钥解密才能得到Pre-master Key。
Certificate Verify(可选)
只有在客户端在发送了证书到服务端时,这个消息才需要发送,其中包含签名,对从握手第一条消息以来的所有握手消息的HMAC值(用master_secret)进行签名。
SSL第四阶段
完成握手协议,建立SSL连接。
该阶段有四个消息交互,前两个为客户端发送,后两个为服务器发送。
建立起一个安全的连接,客户端发送一个Change Cipher spec消息,并且把协商得到的Cipher suite拷贝到当前连接的状态之中。然后客户端使用新的算法和密钥参数发送一个Finished消息,这条消息可以检测密钥交换和认证过程是否已经成功,其中包括一个校验值,对客户端整个握手消息进行校验。服务器同样发送一个Change Cipher Spec消息和Finished消息。握手过程完成,客户端和服务器可以交换应用层数据进行通信。
Change Cipher Spec
编码改变通知,表示随后的信息将用双方商定的加密算法和和密钥发送(ChangeCipherSpec是一个独立的协议,体现在数据包中就是一个字节的数据,用于告知服务端,客户端已经切换到之前协商好的加密套件(Cipher Suite)的状态,准备使用之前协商好的加密套件加密数据并传输了)。
Client finished
客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时也是前面所有发送的内容的hash值,用来供服务器校验。(使用HMAC算法计算收到和发送的所有握手消息的摘要,加密后发送。此数据是为了在正式传输应用数据之前对刚刚握手建立起来的加解密通道进行验证。)
Server Finished
服务端握手结束通知。
使用私钥解密加密的Pre-master数据,基于之前(Client Hello 和 Server Hello)交换的两个明文随机数 random_C 和 random_S,计算得到协商密钥:enc_key=Fuc(random_C, random_S, Pre-Master);
计算之前所有接收信息的hash值,然后解密客户端发送的 encrypted_handshake_message,验证数据和密钥正确性;
发送一个Change Cipher Spec(告知客户端已经切换到协商过的加密套件状态,准备使用加密套件和 Session Secret加密数据了)
服务端也会使用Session Secret加密一段Finish消息发送给客户端,以验证之前通过握手建立起来的加解密通道是否成功。
根据之前的握手信息,如果客户端和服务端都能对Finish信息进行正常加解密且消息正确的被验证,则说明握手通道已经建立成功,接下来,双方可以使用上面产生的Session Secret对数据进行加密传输了。
SSL原理—会话恢复
会话恢复是指只要客户端和服务器已经通信过一次,它们就可以通过会话恢复的方式来跳过整个握手阶段而直接进行数据传输。SSL采用会话恢复的方式来减少SSL握手过程中造成的巨大开销。此功能从之前的13步减少到6步,大大减少了开销。
两种会话机制
会话标识 session ID: 由服务器端支持,协议中的标准字段,因此基本所有服务器都支持,服务器端保存会话ID以及协商的通信信息,Nginx 中1M 内存约可以保存4000个 session ID 机器相关信息,占用服务器资源较多;
会话记录 session ticket :需要服务器和客户端都支持,属于一个扩展字段,支持范围约60%(无可靠统计与来源),将协商的通信信息加密之后发送给客户端保存,密钥只有服务器知道,占用服务器资源很少。
二者对比,主要是保存协商信息的位置与方式不同,类似与 http 中的 session 与 cookie。二者都存在的情况下,(nginx 实现)优先使用 session_ticket。
恢复过程
如果服务器和客户端之间曾经建立过连接,服务器会在握手成功后返回一个session ID,并保存对应的参数在服务器中。如果客户端和服务器需要再次连接,则需要在Client hello消息中携带记录的信息,返回给服务器。服务器根据收的到的Session ID检索缓存记录,如果有缓存,则返回一个Change Cipher Spec消息和Finished消息,如果没有缓存则正常进行握手。如果客户端能够验证通过服务器加密数据,则同样回复一个Change Cipher Spec消息和Finished消息。服务器验证通过则握手建立成功,开始进行正常的加密数据通信。
SSL记录协议
SSL记录协议主要用于实现对数据的分块、加密解密、压缩解压缩、完整性检测和封装各种高层协议。
主要包括:
内容类型
协议版本号
记录数据的长度
数据有效载荷
散列算法计算消息认证代码
将上层分下来的数据包分成合适的数据块,但是每个数据块不得超过214字节。
对每个数据块进行压缩,但是不能丢失数据信息。
计算压缩后的数据消息认证码MAC,并添加在压缩包后。添加后总长度不得超过2262字节。
对称密码加密。
给SSL添加一个首部。其中包括:内容类型、主要版本、次要版本、压缩长度等信息。通过以上过程把原始的数据加密为SSL协议的记录集。
ref:https://blog.csdn.net/weixin_44811851/article/details/122003061
HTTPS
HTTPS 也是一个应用层协议. 是在 HTTP 协议的基础上引入了一个加密层(SSL),加解密原理与SSL一样,只不过加解密内容为http协议。
HTTP 协议内容都是按照文本的方式明文传输的. 这就导致在传输过程中出现一些被篡改的情况。
臭名昭著的 “运营商劫持”
下载一个 天天动听
未被劫持的效果, 点击下载按钮, 就会弹出天天动听的下载链接.
被劫持的效果, 点击下载按钮, 就会弹出qq浏览器的下载链接.
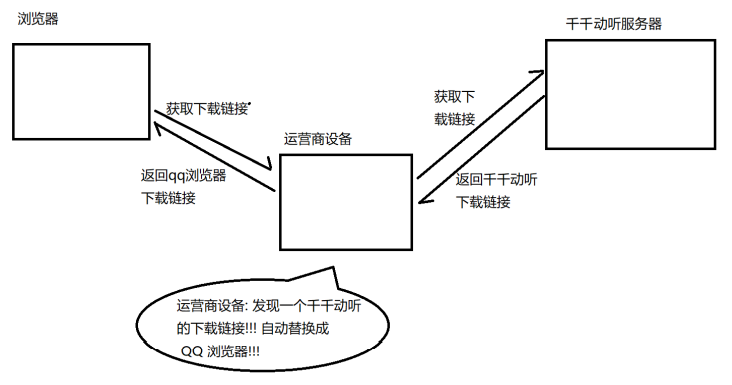
不止运营商可以劫持, 其他的 黑客 也可以用类似的手段进行劫持, 来窃取用户隐私信息, 或者篡改内容。
试想一下, 如果黑客在用户登陆支付宝的时候获取到用户账户余额, 甚至获取到用户的支付密码…
在互联网上, 明文传输是比较危险的事情!!!
HTTPS 就是在 HTTP 的基础上进行了加密, 进一步的来保证用户的信息安全.
“加密” 是什么
加密就是把 明文 (要传输的信息)进行一系列变换, 生成 密文 。
解密就是把 密文 再进行一系列变换, 还原成 明文 。
在这个加密和解密的过程中, 往往需要一个或者多个中间的数据, 辅助进行这个过程, 这样的数据称为 密钥。
回到目录…
HTTPS 的工作过程
既然要保证数据安全, 就需要进行 “加密”。
网络传输中不再直接传输明文了, 而是加密之后的 “密文”。
加密的方式有很多, 但是整体可以分成两大类: 对称加密 和 非对称加密。
2-1 引入对称加密
对称加密其实就是通过同一个 “密钥” , 把明文加密成密文, 并且也能把密文解密成明文。
一个简单的对称加密, 按位异或:明文 a = 1234, 密钥 key = 8888
①引入对称加密之后, 即使数据被截获, 由于黑客不知道密钥是啥, 因此就无法进行解密, 也就不知道请求的真实内容。
②服务器同一时刻其实是给很多客户端提供服务的。这么多客户端用的秘钥都必须是不同的(相同密钥容易扩散)。因此服务器就需要维护每个客户端和每个密钥之间的关联关系。
③客户端如何获取密钥?
如果直接把密钥明文传输, 那么黑客也就能获得密钥了。
因此密钥的传输也必须加密传输!所以就需要引入非对称加密。
2-2 引入非对称加密
非对称加密要用到两个密钥,一个叫做 “公钥”,一个叫做 “私钥”。
公钥和私钥是配对的。最大的缺点就是运算速度非常慢,比对称加密要慢很多。
可以公钥加密、私钥解密,也可以私钥加密、公钥解密。
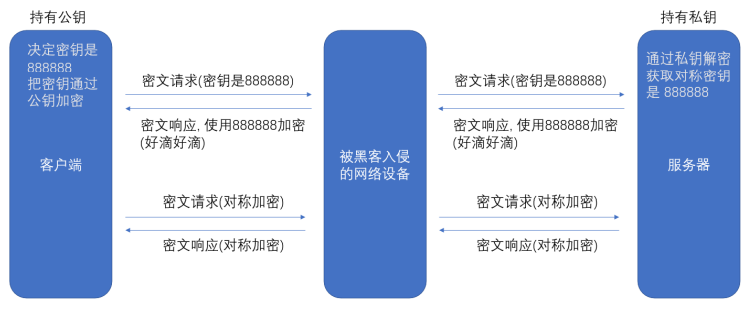
客户端在本地生成对称密钥, 通过公钥加密, 发送给服务器。
由于中间的网络设备没有私钥, 即使截获了数据, 也无法还原出内部的原文, 也就无法获取到对称密钥。
服务器通过私钥解密, 还原出客户端发送的对称密钥。并且使用这个对称密钥加密给客户端返回的响应数据。
后续客户端和服务器的通信都只用对称加密即可。由于该密钥只有客户端和服务器两个主机知道, 其他主机/设备不知道密钥即使截获数据也没有意义。
由于对称加密的效率比非对称加密高很多, 因此只是在开始阶段协商密钥的时候使用非对称加密,后续的传输仍然使用对称加密。
那么接下来问题又来了:
客户端如何获取到公钥?
客户端如何确定这个公钥不是黑客伪造的?
2-3 引入证书
在客户端和服务器刚一建立连接的时候, 服务器给客户端返回一个 证书。
这个证书包含了刚才的公钥, 也包含了网站的身份信息。
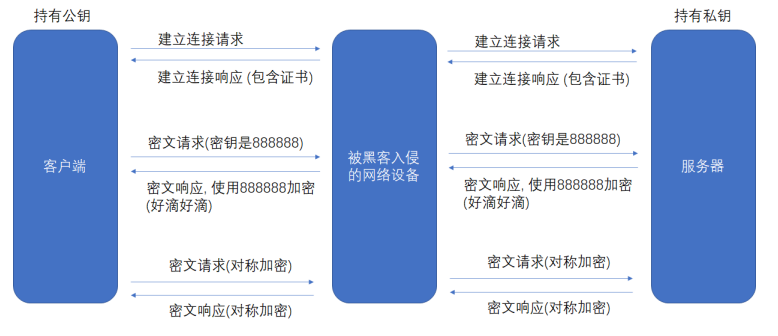
这个 证书 可以理解成是一个结构化的字符串, 里面包含了以下信息:
证书发布机构
证书有效期
公钥
证书所有者
签名
…
当客户端获取到这个证书之后, 会对证书进行校验(防止证书是伪造的):
判定证书的有效期是否过期
判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构).
验证证书是否被篡改:从系统中拿到该证书发布机构的公钥,对签名解密,得到一个 hash 值,设为 hash1。然后计算整个证书的 hash 值,设为hash2。对比 hash1 和 hash2 是否相等,如果相等, 则说明证书是没有被篡改过的。
三、具体过程
HTTPS 工作过程中涉及到的密钥有三组:
第一组(非对称加密):为了让客户端拿到含有私钥-公钥 对的证书。服务器持有私钥(私钥在注册证书时获得),客户端持有公钥(操作系统包含了可信任的 CA 认证机构有哪些, 同时持有对应的公钥)。服务器使用这个私钥对证书的签名进行加密。客户端通过这个公钥解密获取到证书的签名,从而校验证书内容是否是篡改过。
第二组(非对称加密):为了让服务器拿到对称加密的密钥。服务器生成这组 私钥-公钥 对,然后通过证书把公钥传递给客户端。然后客户端用这个公钥给 生成的对称加密的密钥 加密,传输给服务器,服务器通过私钥解密获取到对称加密密钥。
第三组(对称加密):客户端和服务器后续传输的数据都通过这个对称密钥加密解密。
ref:https://blog.csdn.net/qq15035899256/article/details/126430171
Websocket
WebSocket 是一种网络通信协议。RFC6455 定义了它的通信标准。
http是一种无状态,无连接,单向的应用层协议,它采用了请求/响应模型,通信请求只能由客户端发起,服务端对请求做出应答处理。这样的弊端显然是很大的,只要服务端状态连续变化,客户端就必须实时响应,都是通过javascript与ajax进行轮询,这样显然是非常麻烦的,同时轮询的效率低,非常的浪费资源(http一直打开,一直重复的连接)。
于是就有了websocket,它是一种全面双工通讯的网络技术,任意一方都可以建立连接将数据推向另一方,websocket只需要建立一次连接,就可以一直保持
WebSocket工作原理
- 握手(建立连接),web浏览器和服务器都必须使用websocket来建立维护连接,也可以理解为HTTP握手 (handshake)和TCP数据传输
- 浏览器向http一样发起一个请求,等待服务器响应
服务器返回握手响应,告诉浏览器将后续的数据按照websocket的制定格式传输过来 - 服务器接收到了之后,服务器与浏览器之间连接不中断,此时连接已经是双工的了
- 浏览器和服务器由任何需要传输的数据时使用长连接来进行数据传递;
websocket握手过程
1、浏览器、服务器建立TCP连接,三次握手。这是通信的基础,传输控制层,若失败后续都不执行。
2、TCP连接成功后,浏览器通过HTTP协议向服务器传送WebSocket支持的版本号等信息。(开始前的HTTP握手)
3、服务器收到客户端的握手请求后,同样采用HTTP协议回馈数据。
4、当收到了连接成功的消息后,通过TCP通道进行传输通信。
websocket协议头
请求
1 | |
- Upgrade: 向服务器指定协议类型,告诉web服务器当前使用的是websocket协议
- Sec-WebSocket-Key:是一个 Base64 encode 的值,这个是浏览器随机生成的
- Sec-WebSocket-Version:websocket协议版本
响应
1 | |
- 响应头详解(web服务返回状态码101表示协议切换成功)
- Sec-WebSocket-Accept: 是经过服务器确认,并且加密过后的 Sec-WebSocket-Key。用来证明客户端和服务器之间能进行通信了。
数据帧格式
在 WebSocket 协议中,客户端与服务端数据交换的最小信息单位叫做帧(frame),由 1 个或多个帧按照次序组成一条完整的消息(message)。
数据传输的格式是由ABNF 来描述的。
WebSocket 数据帧的统一格式如下图:
1 | |
上面图中名词解释:
| 名词 | 说明 | 大小 |
|---|---|---|
| FIN | 如果是 1,表示这是消息(message)的最后一个分片(fragment);如果是 0,表示不是是消息(message)的最后一个分片(fragment) | 1 个比特 |
| RSV1, RSV2, RSV3 | 一般情况下全为 0。当客户端、服务端协商采用 WebSocket 扩展时,这三个标志位可以非 0,且值的含义由扩展进行定义。如果出现非零的值,且并没有采用 WebSocket 扩展,连接出错 | 各占 1 个比特 |
| opcode | 操作代码,Opcode 的值决定了应该如何解析后续的数据载荷(data payload)。如果操作代码是不认识的,那么接收端应该断开连接(fail the connection) | 4 个比特 |
| mask | 表示是否要对数据载荷进行掩码操作。从客户端向服务端发送数据时,需要对数据进行掩码操作;从服务端向客户端发送数据时,不需要对数据进行掩码操作。 如果服务端接收到的数据没有进行过掩码操作,服务端需要断开连接。 如果 Mask 是 1,那么在 Masking-key 中会定义一个掩码键(masking key),并用这个掩码键来对数据载荷进行反掩码。所有客户端发送到服务端的数据帧,Mask 都是 1。 | 1 个比特 |
| Payload length | 数据载荷的长度,单位是字节。假设数 Payload length === x,如果: x 为 0~126:数据的长度为 x 字节。 x 为 126:后续 2 个字节代表一个 16 位的无符号整数,该无符号整数的值为数据的长度。 x 为 127:后续 8 个字节代表一个 64 位的无符号整数(最高位为 0),该无符号整数的值为数据的长度。 此外,如果 payload length 占用了多个字节的话,payload length 的二进制表达采用网络序(big endian,重要的位在前)。 | 为 7 位,或 7+16 位,或 1+64 位。 |
| Masking-key | 所有从客户端传送到服务端的数据帧,数据载荷都进行了掩码操作,Mask 为 1,且携带了 4 字节的 Masking-key。如果 Mask 为 0,则没有 Masking-key。 备注:载荷数据的长度,不包括 mask key 的长度。 | 0 或 4 字节(32 位 |
| Payload data | 载荷数据:包括了扩展数据、应用数据。其中,扩展数据 x 字节,应用数据 y 字节。The “Payload data” is defined as “Extension data” concatenated with “Application data”. 扩展数据:如果没有协商使用扩展的话,扩展数据数据为 0 字节。所有的扩展都必须声明扩展数据的长度,或者可以如何计算出扩展数据的长度。此外,扩展如何使用必须在握手阶段就协商好。如果扩展数据存在,那么载荷数据长度必须将扩展数据的长度包含在内。 应用数据:任意的应用数据,在扩展数据之后(如果存在扩展数据),占据了数据帧剩余的位置。载荷数据长度 减去 扩展数据长度,就得到应用数据的长度。 | (x+y) 字节 |
表中 opcode 操作码:
- %x0:表示一个延续帧(continuation frame)。当 Opcode 为 0 时,表示本次数据传输采用了数据分片,当前收到的数据帧为其中一个数据分片。
- %x1:表示这是一个文本帧(frame),text frame
- %x2:表示这是一个二进制帧(frame),binary frame
- %x3-7:保留的操作代码,用于后续定义的非控制帧。
- %x8:表示连接断开。connection close
- %x9:表示这是一个 ping 操作。a ping
- %xA:表示这是一个 pong 操作。a pong
- %xB-F:保留的操作代码,用于后续定义的控制帧。
ref:https://blog.csdn.net/new9232/article/details/124208409
ref:https://blog.csdn.net/Huang_Ds/article/details/125671913
ref: https://www.shuzhiduo.com/A/x9J2A1WKz6/
Protobuf
Protobuf 是由 Google 开发的一种语言无关,平台无关,可扩展的序列化结构数据的方法,可用于通信和数据存储。
1)跨语言,跨平台
Protobuf 和语言,平台无关,定义好 pb 文件之后,对于不同的语言使用不同的语言的编译器对 pb 文件进行编译即可,编译完成之后就会提供对应语言能够使用的接口,通过这些接口就可以访问在 pb 文件中定义好的内容了。
2)性能优越
Protobuf 十分高效,无论是在数据存储还是通信性能都非常好,序列化的体积很小,序列化的速度也很快,关于这一点会在后面第 3 节序列化原理章节中做详细的介绍。
3)兼容性好
Protobuf 的兼容性特别好,当我们更新数据的时候不会影响原有的程序,例如 int32 和 int64 是两种不同的类型,存储的数据占用的字节数也不同,但是如果现在需要存储一个负数,采用 Varints 编码时,它们都会占用固定的十个字节,这是为了防止用户在将 int64 改为 int32 时会影响原有的程序。关于这方面的内容,在第3节也会做详细的介绍。
Protobuf, JSON, XML 的区别
Protobuf 和 JSON,XML 既有相似点又有不同点,从数据结构化和数据序列化两个维度去进行比较可能会更直观一些。
数据结构化主要面向开发和业务层面,数据序列化主要面向通信和存储层面。当然数据序列化也需要结构和格式,所以这两者的区别主要在于应用领域和场景不同,因此要求和侧重点也会有所不同。
数据结构化更加侧重于人类的可读性,强调语义表达能力,而数据序列化侧重效率和压缩。
接下来从这两个维度出发,我们进行一些简单的分析。
XML 作为一种可扩展标记语言,JSON 作为源于 JS 的数据格式,都具有数据结构化的能力。
例如 XML 可以衍生出 HTML(虽然 HTNL 早于 XML,但从概念上讲,HTML 只是预定义标签的 XML),HTML 的作用是标记和表达万维网中资源的结构,以便浏览器更好地展示万维网资源,同时也要尽可能保证其人类可读以便开发人员进行开发,这是面向业务或开发层面的数据结构化。
再如 XML 还可衍生出 RDF/RDFS,进一步表达语义网中资源的关系和语义,同样它强调数据结构化的能力和人类可读。
JSON 也是同理,在很多场景下更多的是体现了数据结构化的能力,例如作为交互接口的数据结构的表达。
当然,JSON 和 XML 同样也可以直接被用来数据序列化,实际上很多时候它们也是被这么使用的,例如直接采用 JSON,XML 进行网络通信传输,此时 XML 和 JSON 就成了一种序列化格式,发挥了数据序列化的能力。
但是我们平时开发的时候经常会这么用并不代表就是合理的,或者说是最好的。实际上,将 JSON 和 XML 直接数据序列化进行网络传输通常并不是最优的选择。因为它们在速度、效率,占用空间上都并不是最优的。换句话说它们更适合数据结构化而不是数据序列化。但是如果从这两方面综合考虑或许我们平时的选择又是合理的。
Protobuf 在数据结构化方面可能没有那么突出,但是在数据序列化方面,你会发现 Protobuf 具有明显的优势,效率,速度,空间几乎全面占优,这一部分将会在第 3 节编解码部分做出详细的阐述。
稍微做一个小的总结:
1)XML、JSON、Protobuf 都具有数据结构化和序列化的能力;
2)XML、JSON 更注重数据结构化,关注人类可读性和语义表达能力,Protobuf 更注重数据序列化,关注效率,空间,速度。
3)Protobuf 的应用场景更为明确,一般是在传输数据量较大,RPC 服务数据数据传输,XML、JSON 的应用场景更为丰富,传输数据量较小,在 MongoDB 中采用 JSON 作为查询语句,也是在发挥其数据结构化的能力。
Protobuf 序列化原理
Protobuf 编码结构
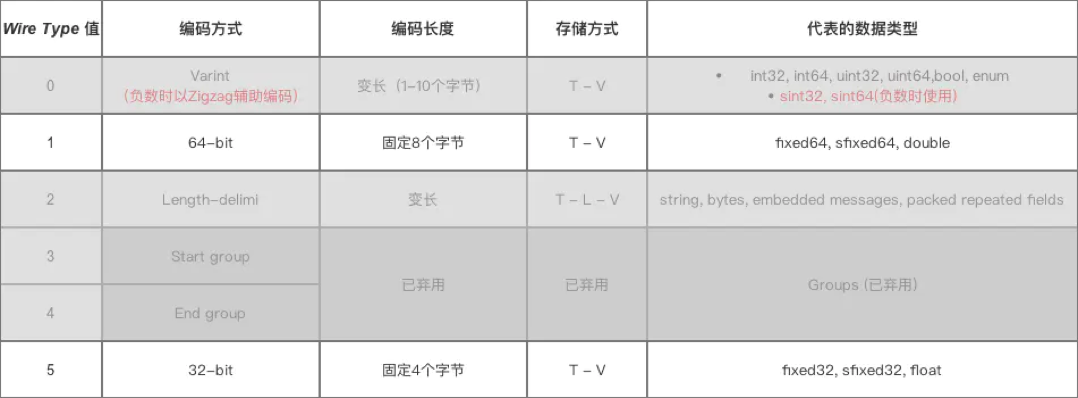
protobuf 数据存储采用 Tag-Length-Value 即标识 - 长度 - 字段值存储方式,以标识 - 长度 - 字段值表示单个字段,最终将数据拼接成一个字节流,从而实现数据存储的功能。
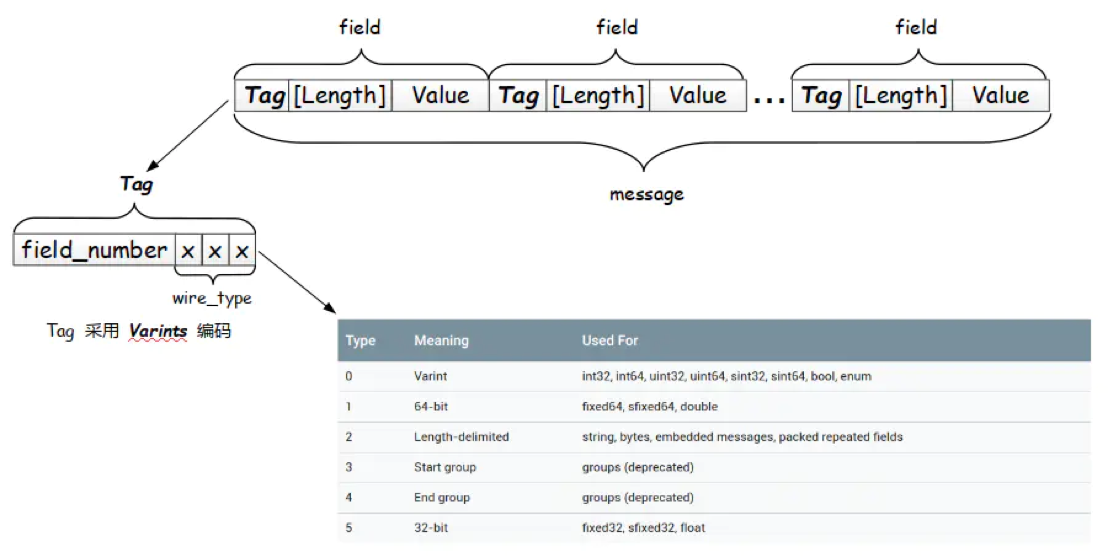
可以看到当采用 T - L - V 的存储结构时不需要分隔符就能分隔开字段,各字段存储地非常紧凑,存储空间利用率非常高。
此外如果某字段没有被设置字段值,那么该字段在序列化时是完全不存在的,即不需要编码,这个字段在解码时才会被设置默认值。
接下来重点介绍一下每个字段中都存在的 Tag。
Tag 由 field_number 和 wire_type 两部分组成,其中 field_number 是字段的标识号,wire_type 是一个数值,根据它的数值可以确定该字段的字段值需要采用的编码类型。
1 | |
wire_type 占 3 bit,最多可以表达 8 种编码类型,目前 Protobuf 已经定义了 6 种(Start group 和 End group 已经被废弃掉了),如下图所示。
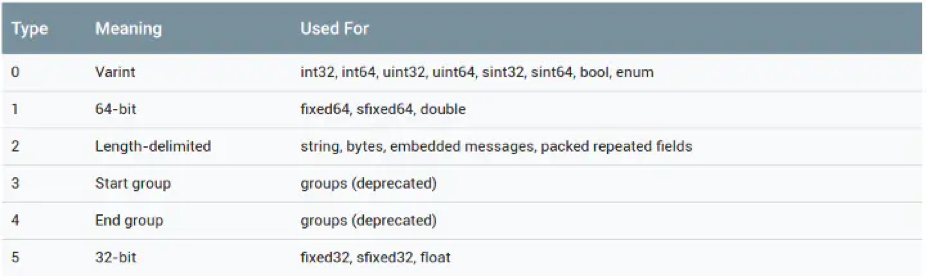
每个字段根据不同的编码类型会有下面两种编码格式:
- Tag - Length - Value: 编码类型表中 Type = 2,即 Length - delimited 编码类型将使用这种结构
- Tag - Value: 编码类型表中 Varint,64-bit,32-bit 将使用这种结构
接下来就来详细地介绍一下各种编码类型。
Varint 编码
Varint 编码是一种变长的编码方式,用字节表示数字,值越小的数字,使用越少的字节数表示。它通过减少表示数字的字节数从而进行数据压缩。
Varint 编码规则
部分源码:
1 | |
从步骤 1 中可以看出,Varint 编码中每个字节的最高位都有特殊的含义:
- 如果是 1,表示后续的字节也是该数字的一部分,需要继续读取
- 如果是 0,表示这是最后一个字节,且剩余 7 位都用来表示数字
所以,当使用 Varint 编码时,只要读取到最高位为 0 的字节时,就表示已经是 Varint 的最后一个字节了。
可以简单地将 Varint 的编码规则归结为以下三点:
1)在每个字节开头的 bit 设置了 msb(most significant bit),标识是否需要继续读取下一个字节
2)存储数字对应的二进制补码
3)补码的低位排在前面
补码的计算方法:
对于正数,原码和补码相同
对于负数,最高位符号位不变,其它位按位取反然后加 1
Varint 编码示例
接下来通过一个示例来说明一下 Varint 编码的过程
示例 1
1 | |
- 原码:0000 … 0000 1000
- 补码:0000 … 0000 1000
- 根据 Varint 编码规则,从低位开始取 7 bit,000 1000
- 当取出前 7 bit 后,前面所有的位就都是 0 了,不需要继续读取了,因此设置 msb 位为 0 即可
- 所以最终 Varint 编码为 0000 1000
可以看到在使用 Varint 编码后只使用一个字节就可以了,而正常的 int32 编码一般需要 4 个字节。
仔细体会上述的 Varint 编码,我们可以发现 Varint 编码本质实际上是每个字节都牺牲了一个 bit 位,来表示是否已经结束(是否需要继续读取下一个字节),msb 实际上就起到了 length 的作用,正因为有了这个 msb 位,所以我们可以摆脱原来那种无论数字大小都必须分配四个字节的窘境。
通过 Varint 编码对于比较小的数字可以用很少的字节进行表示,从而减小了序列化后的体积。
但是由于 Varint 编码每个字节都要拿出一位作为 msb 位,因此每个字节就少了一位来表示字段值。那这就意味着四个字节能表达的最大数字是为 2^28 而不是 2^32 了。
所以如果当数字大于 2^28 时,采用 Varint 编码将导致分配 5 个字节,原先明明只需要 4 个字节。此时 Varint 编码的效率不仅没有提高反而是下降了。
但是这并不影响 Varint 编码在实际应用时的高效,因为事实证明,在大多数情况下,数字在 2^28 ~ 2^32 出现的概率要远远小于 0 ~ 2^28 出现的概率。
示例 2
这样看来 Varint 编码似乎很完美,但是有一种情况下,Varint 编码的效率很低。上面的例子中只给出了正数的情况,思考如果是负数的情况呢。
我们知道负数的二进制表示中最高位是符号位 1,这一点意味着负数都必须占用所有字节。
我们还是通过一个示例来体会一下。
1 | |
- 原码:1000 … 0000 0001
- 补码:1111 … 1111 1111
- 根据 Varints 编码规则,从低位开始取 7 bit,111 1111,由于前面还有 1 需要读取,因此需要设置 msb 位为 1,然后将这个字节放在 Varint 编码的高位。
- 依次类推,有 9 组(字节)都是 1,这 9 组的 msb 均为 1,最后一组只有 1 位是 1,由于已经是最后一组了不需要再继续读取了,因此这组的 msb 位应该是 0.
- 因此最终的 Varint 编码是 1111 1111 … 0000 0001(FF FF FF FF FF FF FF FF FF 01 )
可能大家会有疑问为什么会占用 10 个字节呢?
这是 Protobuf 基于兼容性考虑,例如当开发者将 int64 改为 int32 后应该不影响旧程序,所以将 int32 扩展为 int64 的八个字节。
可能大家还会有疑问为什么对于正数的时候不需要进行类似的兼容处理呢?
实际上当要编码的是正数时,int32 和 int64 是天然兼容的,他们两个的编码过程是完全一样的,利用 msb 位去控制最终的 Varint 编码长度即可。
所以目前的情况是我们定义了一个 int32 类型的变量,如果将变量的值设置为 负数,如果直接采用 Varint 编码的话,其编码结果将总是占用十个字节,这显然不是我们希望得到的结果。那么我们应该如何去解决呢?
答案就是下面的 Zigzag 编码。
Zigzag 编码
在 Protobuf 中 Zigzag 编码的出现主要是为了解决 Varint 编码负数效率低的问题。
基本原理就是将有符号正数映射成无符号整数,然后再使用 Varint 编码,这里所说的映射是通过移位的方式实现的并不是通过存储映射表。
Zigzag 编码规则
部分源码:
1 | |
根据上面的源码我们可以得出 Zigzag 的编码过程如下:
- 将补码左移 1 位,低位补 0,得到 result1
- 将补码右移 31 位,得到 result2
- 首位是 1 的补码(有符号数)是算数右移,即右移后左边补 1
- 首位是 0 的补码(无符号数)是逻辑右移,即右移后左边补 0
- 将 result1 和 result2 异或
Zigzag 编码示例
下面通过一个示例来演示一个 Zigzag 的编码过程
1 | |
- 原码:1000 … 0010
- 补码:1111 … 1110
- 左移一位(算数右移)result1:1111 … 1100
- 右移31位result2:1111 … 1111
- 异或: 0000 … 0011(3)
编码过程示意图如下:
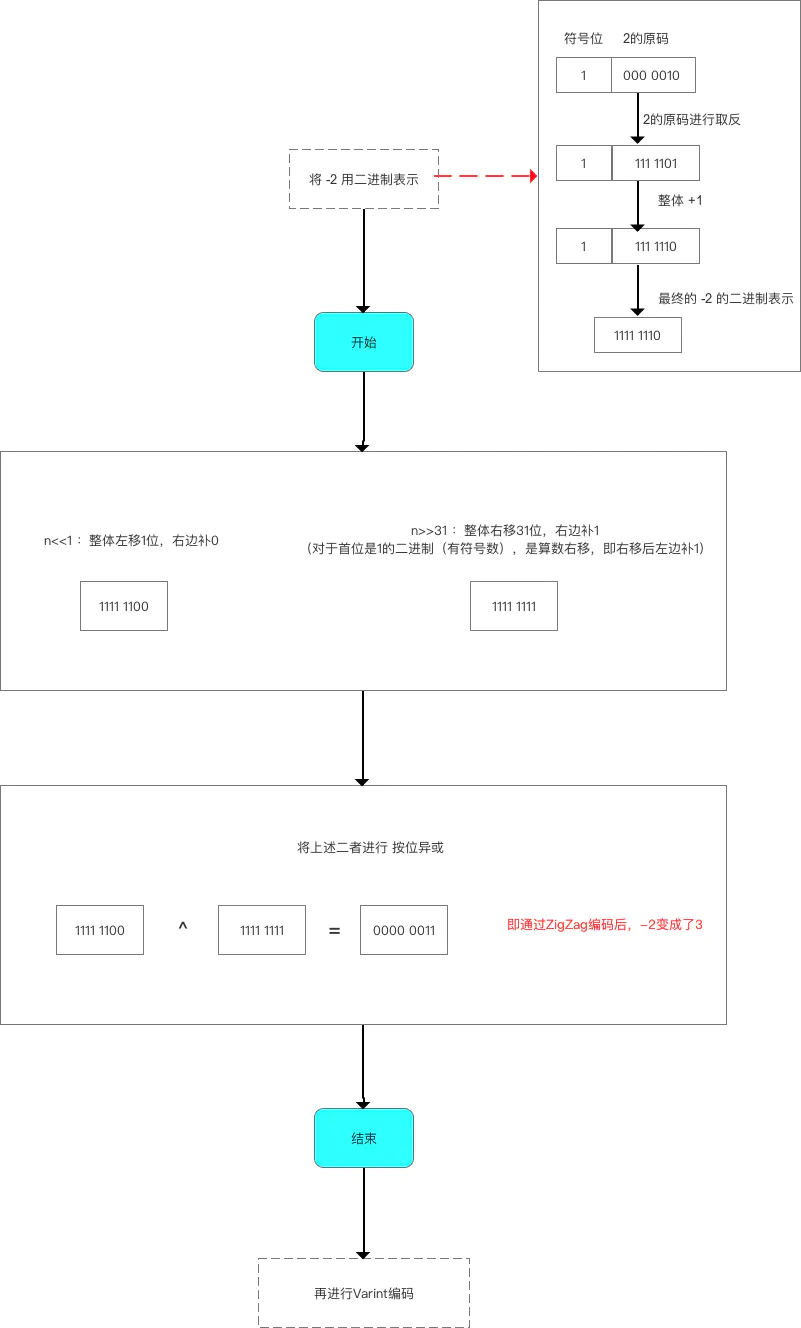
可以看到 -2 经过 Zigzag 编码之后变成了正数 3,这时再通过 Varint 编码就很高效了,在接收端先通过 Varint 解码得到数字 3,然后再通过 Zigzag 解码就可以得到原始发送的数据 -2 了。
因此在定义字段时如果知道该字段的值有可能是负数的话,那么建议使用 sint32/sint64 这两种数据类型。
64-bit(32-bit)编码
64-bit 和 32-bit 的编码方式比较简单,64-bit 编码后是固定的 8 个字节,32 bit 编码后是固定的 4 个字节。当数据类型是 fixed64,sfixed64,double 时将采用 64-bit 编码方式,当数据类型是 fixd32,sfixed64,float 时将采用 32-bit 编码方式。
注意这两种编码方式都是补码的高位放到编码后的低位。
它们都采用的是 T - V 的存储方式。
ength-delimited
这是 Protobuf 中唯一一个采用 T - L - V 的存储方式。如下图所示,Tag 和 Length 仍然采用 Varint 编码,对于字段值根据不同的数据类型采用不同的编码方式。
例如,对于 string 类型字段值采用的是 utf-8 编码,而对于嵌套消息数据类型会根据里面字段的类型选择不同的编码方式。
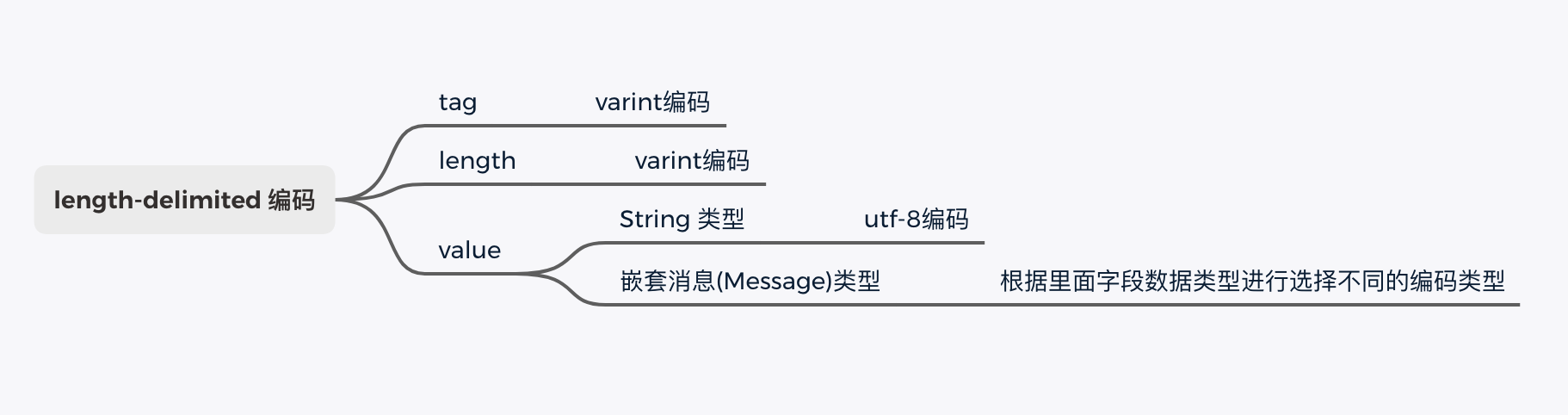
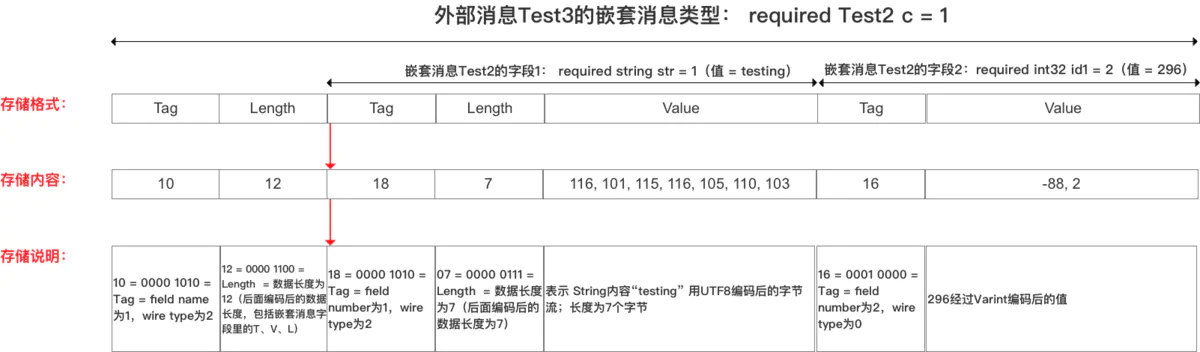
接下来重点说一下嵌套消息数据类型是如何进行编码的。
通过下面的示例来说明,在 Test3 这个 Message 对象中的 c 字段的类型是一个消息对象 Test2,并且将 Test2 中字段 str 的值设置为 testing,将字段 id1 的值设置为 296.
1 | |
那么编码后的存储方式如下:
序列化过程
Protobuf 的性能非常优越主要体现在两点,其中一点就是序列化后的体积非常小,这一点在前面编解码的介绍中已经体现出来了。还有另外一点就是序列化速度非常快,接下来就简单地介绍一下为什么序列化的速度非常快。
Protobuf 序列化的过程简单来说主要有下面两步
- 判断每个字段是否有设置值,有值才进行编码,
- 根据 tag 中的 wire_type 确定该字段采用什么类型的编码方案进行编码即可。
Protobuf 反序列化过程简单来说也主要有下面两步:
- 调用消息类的 parseFrom(input) 解析从输入流读入的二进制字节数据流
- 将解析出来的数据按照指定的格式读取到相应语言的结构类型中
Protobuf 的序列化过程中由于编码方式简单,只需要简单的数学运算位移即可,而且采用的是 Protobuf 框架代码和编译器共同完成,因此序列化的速度非常快。
可能这样并不能很直观地展现出 Protobuf 序列化过程非常快,接下来我们简单介绍一下 XML 的反序列化过程,通过对比我们就能清晰地认识到 Protobuf 序列化的速度是非常快的。
XML 反序列化的过程大致如下:
- 从文件中读取出字符串
- 从字符串转换为 XML 文档对象模型
- 从 XML 文档对象结构模型中读取指定节点的字符串
- 将该字符串转换成指定类型的变量
从上述过程中,我们可以看到 XML 反序列化的过程比较繁琐,而且在第二步,将 XML 文件转换为文档对象模型的过程是需要词法分析的,这个过程是比较耗费时间的,因此通过对比我们就可以感受到 Protobuf 的序列化的速度是非常快的。
使用建议
接下来结合上面所提到的一些知识,简单给出一些在使用 Protobuf 时的一些小建议。
1)如果有负数,那么尽量使用 sint32/sint64 ,不要使用 int32/int64,因为采用 sin32/sin64 数据类型表示负数时,根据前面的介绍可以知道会先采用 Zigzag 将负数通过移位的方式映射为正数, 然后再使用 Varint 编码,这样就可以有效减少存储的字节数。
2)字段标识号的时候尽量只使用 1~15,并且不要跳动使用。因为如果超过 15,那么 Tag 在编码时就会占用更多的字节。如果将字段标识号定义为连续递增的数值,将会获得更好的编码性能和解码性能。
3)尽量多地使用 optional 或 repeated 修饰符(在 proto3 版本中默认是 optional),因为使用这两个修饰符后如果不设置值,在序列化时是不进行编码的,默认值会在反序列化时自动添加。
ref: http://t.zoukankan.com/zhangguicheng-p-14117962.html
DNP3
ZPMC OPC Server支持与电力系统中子站系统,RTU,智能电子设备以及主站系统等通过以太网RS232/485串行通讯,将使用您的计算机中的网卡或串口。本驱动支持的通讯协议为 Distributed Network Protocol 3.0(简称DNP3)协议。
Dnp3协议 一共分为三层 链路层、传输层、应用层
ref: https://www.bbsmax.com/A/mo5kEvo2zw/
DNS
收起
域名的层级结构
查询过程
递归查询和迭代查询
DNS 缓存
DNS 实现负载平衡
DNS 协议提供的是一种主机名到 IP 地址的转换服务,就是我们常说的域名系统。它是一个由分层的 DNS 服务器组成的分 布式数据库,是定义了主机如何 查询这个分布式数据库的方式的应用层协议。DNS 协议运行在 UDP 协议之上, 使用 53 号 端口
域名的层级结构
主机名.次级域名.顶级域名.根域名
即 host.sld.tld.roo
根据域名的层级结构,管理不同层级域名的服务器,
可以分为根域名服务器、顶级域名服务器和权威域名服务器。
查询过程
DNS 的查询过程一般为,我们首先将 DNS 请求发送到本地 DNS 服务器,由 本地 DNS 服务器来代为请求。
\1. 从”根域名服务器”查到”顶级域名服务器”的 NS 记录和 A 记录( IP 地 址)。
\2. 从”顶级域名服务器”查到”次级域名服务器”的 NS 记录和 A 记录( IP 地址)。
\3. 从”次级域名服务器”查出”主机名”的 IP 地址。
比如我们如果想要查询 http://www.baidu.com 的 IP 地址,我们首先会将请求发送到 本地的 DNS 服务器中,本地 DNS 服务 器会判断是否存在该域名的缓存,如 果不存在,则向根域名服务器发送一个请求,根域名服务器返回负责 .com 的 顶级域名 服务器的 IP 地址的列表。然后本地 DNS 服务器再向其中一个负 责 .com 的顶级域名服务器发送一个请求,负责 .com 的顶级域名服务器返回 负责 .baidu 的权威域名服务器的 IP 地址列表。然后本地 DNS 服务器再向其 中一个权威域名服 务器发送一个请求,最后权威域名服务器返回一个对应的主 机名的 IP 地址列
递归查询和迭代查询
递归查询指的是查询请求发出后,域名服务器代为向下一级域名服务器发出请求, 最后向用户返回查询的最终结果。使用递归 查询,用户只需要发出一次查询请 求。
迭代查询指的是查询请求后,域名服务器返回单次查询的结果。下一级的查询由 用户自己请求。使用迭代查询,用户需要发出 多次的查询请求。 一般我们向本地 DNS 服务器发送请求的方式就是递归查询,因为我们只需要发 出一次请求,然后本地 DNS 服务器返回给我 们最终的请求结果。
而本地 DNS 服务器向其他域名服务器请求的过程是迭代查询的过程,因为每一次域名服务器 只返回单次 查询的结果,下一级的查询由本地 DNS 服务器自己进行。
DNS 缓存
DNS 缓存的原理非常简单,在一个请求链中,当某个 DNS 服务器接收到一个 DNS 回答后,它能够将回答中的信息缓存在本 地存储器中。返回的资源记录中 的 TTL 代表了该条记录的缓存的时间
DNS 实现负载平衡
DNS 可以用于在冗余的服务器上实现负载平衡。因为现在一般的大型网站使用 多台服务器提供服务,因此一个域名可能会对应 多个服务器地址。当用户发起 网站域名的 DNS 请求的时候,DNS 服务器返回这个域名所对应的服务器 IP 地址的集合,但在每个回答中,会循环这些 IP 地址的顺序,用户一般会选择排在前面的地址发送请求。以此将用户的请求均衡的分配到各个不同的服务器 上,这样来实现负载均衡。
ref: https://zhuanlan.zhihu.com/p/461210825
Sock5
编程语言
C++
什么是面向对象
面向对象:对象是指具体的某一个事物,这些事物的抽象就是类,类中包含数据(成员变量)和动作(成员方法)。
面向对象的三大特性:
封装:将具体的实现过程和数据封装成一个函数,只能通过接口进行访问,降低耦合性。
继承:子类继承父类的特征和行为,子类有父类的非 private 方法或成员变量,子类可以对父类的方法进行重写,增强了类之间的耦合性,但是当父类中的成员变量、成员函数或者类本身被 final 关键字修饰时,修饰的类不能继承,修饰的成员不能重写或修改。(这里说明一下,其实父类中的private方法也会被继承下来,只不过是不能被访问。)
多态:多态就是不同继承类的对象,对同一消息做出不同的响应,基类的指针指向或绑定到派生类的对象,使得基类指针呈现不同的表现方式。
重载、重写、隐藏的区别
- 重载:是指同一可访问区内被声明几个具有不同参数列(参数的类型、个数、顺序)的同名函数,根据参数列表确定调用哪个函数,重载不关心函数返回类型。
1 | |
- 隐藏:是指派生类的函数屏蔽了与其同名的基类函数,主要只要同名函数,不管参数列表是否相同,基类函数都会被隐藏。
1 | |
- 重写(覆盖):是指派生类中存在重新定义的函数。函数名、参数列表、返回值类型都必须同基类中被重写的函数一致,只有函数体不同。派生类调用时会调用派生类的重写函数,不会调用被重写函数。重写的基类中被重写的函数必须有 virtual 修饰。
重写和重载的区别:
范围区别:对于类中函数的重载或者重写而言,重载发生在同一个类的内部,重写发生在不同的类之间(子类和父类之间)。
参数区别:重载的函数需要与原函数有相同的函数名、不同的参数列表,不关注函数的返回值类型;重写的函数的函数名、参数列表和返回值类型都需要和原函数相同,父类中被重写的函数需要有 virtual 修饰。
virtual 关键字:重写的函数基类中必须有 virtual关键字的修饰,重载的函数可以有 virtual 关键字的修饰也可以没有。
隐藏和重写,重载的区别:
范围区别:隐藏与重载范围不同,隐藏发生在不同类中。
参数区别:隐藏函数和被隐藏函数参数列表可以相同,也可以不同,但函数名一定相同;当参数不同时,无论基类中的函数是否被 virtual 修饰,基类函数都是被隐藏,而不是重写。
explicit 的作用(如何避免编译器进行隐式类型转换)
作用:用来声明类构造函数是显示调用的,而非隐式调用,可以阻止调用构造函数时进行隐式转换。只可用于修饰单参构造函数,因为无参构造函数和多参构造函数本身就是显示调用的,再加上 explicit 关键字也没有什么意义。
隐式转换:
1 | |
上述代码中,A ex = 10; 在编译时,进行了隐式转换,将 10 转换成 A 类型的对象,然后将该对象赋值给 ex,等同于如下操作:
为了避免隐式转换,可用 explicit 关键字进行声明:
1 | |
new 和 malloc 的区别,delete 和 free 的区别
在使用的时候 new、delete 搭配使用,malloc、free 搭配使用。
malloc、free 是库函数,而new、delete 是关键字。
-new 申请空间时,无需指定分配空间的大小,编译器会根据类型自行计算;malloc 在申请空间时,需要确定所申请空间的大小。
new 申请空间时,返回的类型是对象的指针类型,无需强制类型转换,是类型安全的操作符;malloc 申请空间时,返回的是 void* 类型,需要进行强制类型的转换,转换为对象类型的指针。
new 分配失败时,会抛出 bad_alloc 异常,malloc 分配失败时返回空指针。
对于自定义的类型,new 首先调用 operator new() 函数申请空间(底层通过 malloc 实现),然后调用构造函数进行初始化,最后返回自定义类型的指针;delete 首先调用析构函数,然后调用 operator delete() 释放空间(底层通过 free 实现)。malloc、free 无法进行自定义类型的对象的构造和析构。
new 操作符从自由存储区上为对象动态分配内存,而 malloc 函数从堆上动态分配内存。(自由存储区不等于堆)
堆是c语言和操作系统的术语,是操作系统维护的一块内存。自由存储是C++中通过new和delete动态分配和释放对象的抽象概念。
什么是多态?
1)派生类对象的地址可以赋值给基类指针。对于通过基类指针调用基类和派生类中都有的同名、同参数表的虚函数的语句,编译时并不确定要执行的是基类还是派生类的虚函数;而当程序运行到该语句时,如果基类指针指向的是一个基类对象,则基类的虚函数被调用,如果基类指针指向的是一个派生类对象,则派生类的虚函数被调用。这种机制就叫作“多态(polymorphism)”。
2)静态多态(编译阶段,地址早绑定)
函数重载:包括普通函数的重载和成员函数的重载
函数模板的使用:通过将类型作为参数,传递给模板,可使编译器生成该类型的函数。
3)动态多态(运行阶段,地址晚绑定)在程序执行期间(非编译期)判断所引用对象的实际类型,根据其实际类型调用相应的方法。
派生类
虚函数
继承和多态区别与联系?
区别:继承是子类使用父类的方法,而多态则是父类使用子类的方法。
1) 什么是继承,继承的特点?
子类继承父类的特征和行为,使得子类具有父类的各种属性和方法。
2) 什么是多态?
相同的事物,调用其相同的方法,参数也相同时,但表现的行为却不同。
3)继承是为了重用代码,有效实现代码重用,减少重复代码的出现。
4)多态是为了接口重用,增强接口的扩展性。
简述c、C++程序编译的内存分配情况
从静态存储区域分配:
内存在程序 编译 时 就已 经 分配 好,这块内 存在 程序 的整 个运行 期间 都存在 。速 度快、不容易出错 , 因 为 有系 统 会善 后。例 如全 局变 量, sta tic 变量, 常量 字符 串等。
在栈上分配:
在执行函数时, 函数内局部变量的存储单元都在栈上创建,函数执行结束时这些存储单元自动被释放。 栈内存分配运算内置于处理器的指令集中, 效率很高, 但是 分配的内存容量有限 。大小为2M。
从堆上分配:
即动态内存分配。程序在运行的时候用 malloc 或 new 申请任意大小的内存,程序员自己负责在何时用 free 或delete 释放内存。动态内存的生存期由程序员决定,使用非常灵活。如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏 ,另外频繁地分配和释放不同大小的堆空间将会产生堆内碎块 。
虚函数可以内联吗?
当呈现非多态的时候,虚函数可以内联。因为内敛函数是在编译的时候确定函数的执行位置的, 当函数呈现多态的时候,在编译的时候不知道是将基类的函数地址,还是派生类的地址写入虚函数表中,所以当非多态的时候就会将基类的虚函数地址直接写入虚函数表中,然后通过内联将代码地址写入。
引用会占用内存空间吗?
引用类型的变量会占用内存空间,占用的内存空间的大小和指针类型的大小是相同的。
C++程序编译过程
编译过程分为四个过程:编译(编译预处理、编译、优化),汇编,链接。
编译预处理:处理以 # 开头的指令;
编译、优化:将源码 .cpp 文件翻译成 .s 汇编代码;
汇编:将汇编代码 .s 翻译成机器指令 .o 文件;
链接:汇编程序生成的目标文件,即 .o 文件,并不会立即执行,因为可能会出现:.cpp 文件中的函数引用了另一个 .cpp 文件中定义的符号或者调用了某个库文件中的函数。那链接的目的就是将这些文件对应的目标文件连接成一个整体,从而生成可执行的程序 .exe 文件。
链接分为两种:
静态链接:代码从其所在的静态链接库中拷贝到最终的可执行程序中,在该程序被执行时,这些代码会被装入到该进程的虚拟地址空间中。
动态链接:代码被放到动态链接库或共享对象的某个目标文件中,链接程序只是在最终的可执行程序中记录了共享对象的名字等一些信息。在程序执行时,动态链接库的全部内容会被映射到运行时相应进行的虚拟地址的空间。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5QrtRK4a-1649036213702)(C:\Users\ZHAOCHENHAO\Pictures\Camera Roll\image-20220308221305914.png)]
二者的优缺点:
静态链接:浪费空间,每个可执行程序都会有目标文件的一个副本,这样如果目标文件进行了更新操作,就需要重新进行编译链接生成可执行程序(更新困难);优点就是执行的时候运行速度快,因为可执行程序具备了程序运行的所有内容。
动态链接:节省内存、更新方便,但是动态链接是在程序运行时,每次执行都需要链接,相比静态链接会有一定的性能损失。
内存管理
C++ 内存分区:栈、堆、全局/静态存储区、常量存储区、代码区。
栈:存放函数的局部变量、函数参数、返回地址等,由编译器自动分配和释放。
堆:动态申请的内存空间,就是由 malloc 分配的内存块,由程序员控制它的分配和释放,如果程序执行结束还没有释放,操作系统会自动回收。
全局区/静态存储区(.bss 段和 .data 段):存放全局变量和静态变量,程序运行结束操作系统自动释放,在 C 语言中,未初始化的放在 .bss 段中,初始化的放在 .data 段中,C++ 中不再区分了。
常量存储区(.data 段):存放的是常量,不允许修改,程序运行结束自动释放。
代码区(.text 段):存放代码,不允许修改,但可以执行。编译后的二进制文件存放在这里。
栈和堆的区别
申请方式:栈是系统自动分配,堆是程序员主动申请。
申请后系统响应:分配栈空间,如果剩余空间大于申请空间则分配成功,否则分配失败栈溢出;申请堆空间,堆在内存中呈现的方式类似于链表(记录空闲地址空间的链表),在链表上寻找第一个大于申请空间的节点分配给程序,将该节点从链表中删除,大多数系统中该块空间的首地址存放的是本次分配空间的大小,便于释放,将该块空间上的剩余空间再次连接在空闲链表上。
栈在内存中是连续的一块空间(向低地址扩展)最大容量是系统预定好的,堆在内存中的空间(向高地址扩展)是不连续的。
申请效率:栈是有系统自动分配,申请效率高,但程序员无法控制;堆是由程序员主动申请,效率低,使用起来方便但是容易产生碎片。
存放的内容:栈中存放的是局部变量,函数的参数;堆中存放的内容由程序员控制。
智能指针有哪几种?智能指针的实现原理?
智能指针是为了解决动态内存分配时带来的内存泄漏以及多次释放同一块内存空间而提出的。C++11 中封装在了
C++11 中智能指针包括以下三种:
共享指针(shared_ptr):资源可以被多个指针共享,使用计数机制表明资源被几个指针共享。通过 use_count() 查看资源的所有者的个数,可以通过 unique_ptr、weak_ptr 来构造,调用 release() 释放资源的所有权,计数减一,当计数减为 0 时,会自动释放内存空间,从而避免了内存泄漏。
独占指针(unique_ptr):独享所有权的智能指针,资源只能被一个指针占有,该指针不能拷贝构造和赋值。但可以进行移动构造和移动赋值构造(调用 move() 函数),即一个 unique_ptr 对象赋值给另一个 unique_ptr 对象,可以通过该方法进行赋值。
弱指针(weak_ptr):指向 share_ptr 指向的对象,能够解决由shared_ptr带来的循环引用问题。
一个 unique_ptr 怎么赋值给另一个 unique_ptr 对象?
借助 std::move() 可以实现将一个 unique_ptr 对象赋值给另一个 unique_ptr 对象,其目的是实现所有权的转移。
1 | |
C++ 11 新特性
auto 类型推导
auto 关键字:自动类型推导,编译器会在 编译期间 通过初始值推导出变量的类型,通过 auto 定义的变量必须有初始值。
auto 关键字基本的使用语法如下:
1 | |
注意:编译器推导出来的类型和初始值的类型并不完全一样,编译器会适当地改变结果类型使其更符合初始化规则。
lambda 表达式
lambda 表达式,又被称为 lambda 函数或者 lambda 匿名函数。
lambda匿名函数的定义:
1 | |
其中:
capture list:捕获列表,指 lambda 所在函数中定义的局部变量的列表,通常为空。
return type、parameter list、function body:分别表示返回值类型、参数列表、函数体,和普通函数一样。
举例:
1 | |
右值引用
右值引用的出现是为了解决两个问题的,第一个问题是临时对象非必要的昂贵的拷贝操作,第二个问题是在模板函数中如何按照参数的实际类型进行转发。通过右值引用,很好的解决两个问题。
右值引用考察的纪律还是挺高的,也挺重要的,看了很多关于右值引用的介绍,这篇文章是我看过右值引用最好的文章,必看:从四行代码看右值引用.
引用,就是为了避免复制而存在,而左值引用和右值引用是为了不同的对象存在:
左值引用的对象是变量
右值引用的对象是常量
1 | |
智能指针
volatile 的作用?是否具有原子性,对编译器有什么影响?
volatile 的作用:当对象的值可能在程序的控制或检测之外被改变时,应该将该对象声明为 violatile,告知编译器不应对这样的对象进行优化。
volatile不具有原子性。
volatile 对编译器的影响:使用该关键字后,编译器不会对相应的对象进行优化,即不会将变量从内存缓存到寄存器中,防止多个线程有可能使用内存中的变量,有可能使用寄存器中的变量,从而导致程序错误。
ref:https://blog.csdn.net/Awesomewan/article/details/123948929
QT
Qt信号和槽的本质是什么
回调函数。信号或是传递值,或是传递动作变化;槽函数响应信号或是接收值,或者根据动作变化来做出对应操作。
描述QT中的文件流(QTextStream)和数据流(QDataStream)的区别
文件流(QTextStream)。操作轻量级数据(int,double,QString)数据写入文本件中以后以文本的方式呈现。
数据流(QDataStream)。通过数据流可以操作各种数据类型,包括对象,存储到文件中数据为二进制。
文件流,数据流都可以操作磁盘文件,也可以操作内存数据。通过流对象可以将对象打包到内存,进行数据的传输。
ref:https://blog.csdn.net/qq_35693630/article/details/122807833
libevent
Libevent是一个轻量级的开源高性能网络库
libevent简介
上来当然要先夸奖啦,Libevent 有几个显著的亮点:
=> 事件驱动(event-driven),高性能;
=> 轻量级,专注于网络,不如ACE那么臃肿庞大;
=> 源代码相当精炼、易读;
=> 跨平台,支持Windows、Linux、*BSD和Mac Os;
=> 支持多种I/O多路复用技术, epoll、poll、dev/poll、select和kqueue等;
=> 支持I/O,定时器和信号等事件;
=> 注册事件优先级;
Libevent已经被广泛的应用,作为底层的网络库;比如memcached、Vomit、Nylon、Netchat等等。
采用的是epoll 反应堆模型。
boost
Boost常用的库很多都已经被包含到C++11、C++14或者C++17中了。
这里还是按照Boost程序库完全开发指针的目录结构进行总结。
常用功能库:
关于时间的 chrono库, 已被加入C++11标准。
关于随机数的random库,已被加入C++11标准。
关于正则表达式的regex库,已被加入C++11标准。
内存管理:
包括智能指针
scoped_ptr, 对于C++11中的unique_ptr。
shared_ptr, 已被加入C++11标准。
weak_ptr,已被加入C++11标准。
scoped_array
shared_array
scoped_array/shared_array是scoped_ptr/shared_ptr对动态数组的扩展,它们为动态数组提供了可自动删除的代理,shared_array比scoped_array有更多的用途,但我们应该使用vector和shared_ptr,除非程序对性能有非常苛刻的要求。
使用工具:
noncopyable,允许程序轻松实现一个禁止拷贝的类。它将拷贝构造函数和拷贝赋值函数设置为private,禁止进行拷贝和赋值。将默认构造函数设置为protected,禁止直接产出无意义的noncopyable对象。
ignore_unused,使用可变参数模板,可以支持任意数量、任意类型的变量,把它们作为函数的参数“使用”了一下,达到了与(void)var完全相同的效果。但它的命名更清晰,写法更简单,而且由于是inline函数,完全没有运行时的效率损失。
uuid, 用来生成全局唯一的UUID。
容器与数据结构:
定长数组类array,已被加入C++11标准。
散列容器(无序关联容器)unordered_set、unordered_mulitset、unordered_map、unordered_multimap,已被加入C++11标准。
环形缓冲区circular_buffer。
元组tuple,已被加入C++11标准。
any,用来容纳任何类型的元素。 已被加入C++17标准。
函数与回调:
ref库,定义了一个很小很简单的引用类型的包装器,可以用来进行引用传递。 已被加入C++11标准。
bind库,是对C++98标准中函数适配器bind1st/bind2nd的泛化和增强,可以适配任意的可调用对象,包括函数指针,函数引用,成员函数指针和函数对象。已被加入到C++11标准。
function是一个函数对象的“容器”,概念上像是C/C++中函数指针类型的泛化,是一种“智能函数指针”。它以对象的形式封装了原始的函数指针或函数对象,能够容纳任意符合函数签名的可调用对象。因此可以被用于回调机制,暂时保管函数或函数对象,在之后需要的时机再调用,使回调机制拥有更多的弹性。 已被加入到C++11标准。
并发编程:
atomic实现原子操作。它封装了不同计算机硬件的底层操作原语,提供了跨平台的原子操作功能,让我们完全摆脱并发编程读写变量的困扰。
thread库实现了操作系统里的线程表示,赋值启动和管理线程对象。
asio库基于前摄器模式封装了操作系统的select、kqueue、poll/epoll、overlapped I/O 等机制,实现了异步IO模型。
ref:https://blog.csdn.net/xp178171640/article/details/105405950
C
空结构体多少个字节?
1字节,实例化的时候需要分配内存
用const修饰一个函数有什么作用?
防止修改成员变量
IO多路复用概念
IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程。
其实就是在单个线程中通过记录跟踪每一个I/O流的状态来管理多个I/O流。
select
select基于fd_set结构体(一个long类型数组),数组内的每一个元素都与一个fd相关联。select是基于遍历来查找fd事件的,所以时间复杂度为O(n)。
select在监听过程中,每次需要把fd列表从用户态拷贝到内核态,然后再遍历所有fd,判断有无读写事件发生。这也导致select在监听IO数量较多的情况下,性能开销极大(poll也有这个缺点)
为了减少数据拷贝带来的性能损坏,所以内核对单个进程可监视的fd数量做了限制。
水平触发:如果用户程序没有处理select所报告的fd,则下一次select时会继续报告此fd。
poll
poll与select的机制基本一致。由于poll是基于链表存储fd关联的,所以poll没有最大连接数限制。poll也是基于遍历来查找fd事件的,时间复杂度也是O(n)。
水平触发:如果用户程序没有处理poll所报告的fd,则下一次poll时会继续报告此fd。
poll的缺点:
和select一样,每次都把全部fd拷贝进内核态,再从中遍历查找有新事件的fd,性能开销大。
epoll
epoll底层是基于哈希表和回调函数的,所以时间复杂度为O(1)。
epoll有两种模式,LT和ET,LT是默认的模式,
ET是高速模式(边缘触发)。
LT模式(水平触发):epoll_wait检测到某fd事件就绪并通知用户程序时,如果用户程序不处理该事件,则每次epoll_wait都会返回这个fd事件,不断提醒用户程序去操作。
ET模式(边缘触发):当一个fd里有新的数据变化时,epoll只会向用户程序返回一次报告,直到下次再有新的数据流入之后,才会再次返回报告,无论fd中是否还有数据可读。
epoll的优点:
不会像select或poll那样因为打开的fd过多而影响性能。
没有最大并发限制连接xiao限制。
epoll在监听到fd变化后不必像select或poll那样返回整个fd列表来进行遍历查找,而是只将产生变化的fd(即活跃的fd)放入一个列表中,调用callback函数返回。
使用了mmap技术,利用mmap()文件映射内存加速与内核空间的消息传递。
epoll存在的问题:
当活跃连接数过多时可能会有性能问题。
epoll机制需要很多回调函数,在连接数较少的情况下,性能可能不如select和poll。
ref: https://blog.csdn.net/weixin_45743893/article/details/122970342
Go
go的调度
答:
go的调度原理是基于GMP模型,G代表一个goroutine,不限制数量;M=machine,代表一个线程,最大1万,所有G任务还是在M上执行;P=processor代表一个处理器,每一个允许的M都会绑定一个G,默认与逻辑CPU数量相等(通过runtime.GOMAXPROCS(runtime.NumCPU())设置)。
go调用过程
创建一个G对象
如果还有空闲的的P,创建一个M
M会启动一个底层线程,循环执行能找到的G
G的执行顺序是先从本地队列找,本地没找到从全局队列找。
一次性转移(全局G个数/P个数)个,再去其它P中找(一次性转移一半)以上的G任务是按照队列顺序执行(也就是go函数的调用顺序)。
另外在启动时会有一个专门的sysmon来监控和管理,记录所有P的G任务计数schedtick。如果某个P的schedtick一直没有递增,说明这个P一直在执行一个G任务,如果超过一定时间就会为G增加标记,并且该G执行非内联函数时中断自己并把自己加到队尾。
go struct能不能比较
可以能,也可以不能。
因为go存在不能使用==判断类型:map、slice,如果struct包含这些类型的字段,则不能比较。
这两种类型也不能作为map的key。
####go defer(for defer)
答:
类似栈操作,后进先出。
因为go的return是一个非原子性操作,比如语句 return i,实际上分两步进行,即将i值存入栈中作为返回值,然后执行跳转,而defer的执行时机正是跳转前,所以说defer执行时还是有机会操作返回值的。
select可以用于什么
答:
- goroutine超时设置,防止goroutine一直执行导致内存不释放等问题。
- 判断channel是否已满或空。如实现一个池线程,当channel已被写满,暂无空闲worker在进行读取,进入default,返回一个暂无可分配资源错误。
select的case的表达式必须是一个channel类型,所有case都会被求值,求值顺序自上而下,从左至右。如果多个case可以完成,则会随机执行一个case,如果有default分支,则执行default分支语句。如果连default都没有,则select语句会一直阻塞,直到至少有一个IO操作可以进行。
break关键字可跳出select的执行。
context包的用途
goroutine管理、信息传递。context的意思是上下文,在线程、协程中都有这个概念,它指的是程序单元的一个运行状态、现场、快照,包含。context在多个goroutine中是并发安全的。
ref: https://blog.csdn.net/lxw1844912514/article/details/108519770
C#
C#中堆和栈的区别?
栈:由编译器自动分配、释放。在函数体中定义的变量通常在栈上。 堆:一般由程序员分配释放。用 new、 malloc 等分配内存函数分配得到的就是在堆上。 存放在栈中时要管存储顺序,保持着先进后出的原则,他是一片连续的内存域,有系统自动分配和维护;
堆:是无序的,他是一片不连续的内存域,有用户自己来控制和释放,如果用户自己不释放的话,当内存达到一定的特定值时,通过垃圾回收器(GC) 来回收。
栈内存无需我们管理,也不受 GC 管理。当栈顶元素使用完毕,立马释放。而堆则需要 GC 清理。
使用引用类型的时候,一般是对指针进行的操作而非引用类型对象本身。但是值类型则操作其本身
C#中的委托是什么?事件是不是一种委托?
委托的本质是一个类,委托是将一种方法作为参数代入到另一种方法。 事件是委托的实例,事件是一种 特殊的委托。 // 比如: onclick 事件中的参数就是一种方法。
C#静态构造函数特点是什么?
最先被执行的构造函数,且在一个类里只允许有一个无参的静态构造函数
执行顺序:静态变量 > 静态构造函数 > 实例变量 > 实例构造函数
CTS、CLS、CLR分别作何解释
CTS :通用语言系统。 CLS :通用语言规范。 CLR :公共语言运行库。
CTS : Common Type System 通用类型系统。 Int32 、 Int16 → int 、 String → string 、 Boolean → bool 。
每种语言都定义了自己的类型, .NET 通过 CTS 提供了公共的类型,然后翻译生成对应的 .NET 类型。
CLS : Common Language Specification 通用语言规范。不同语言语法的不同。每种语言都有自己的语法,.NET 通过 CLS 提供了公共的语法,然后不同语言翻译生成对应的 .NET 语法。
CLR : Common Language Runtime 公共语言运行时,就是 GC 、 JIT 等这些。有不同的 CLR ,比如服务器
CLR 、 Linux CLR ( Mono )、 Silverlight CLR(CoreCLR) 。相当于一个发动机,负责执行 IL 。
C#中什么是值类型与引用类型?
值类型: struct 、 enum 、 int 、 float 、 char 、 bool 、 decimal
引用类型: class 、 delegate 、 interface 、 array 、 object 、 string
请详述在C#中类(class)与结构(struct)的异同?
class 可以被实例化 , 属于引用类型 ,
class 可以实现接口和单继承其他类 , 还可以作为基类型 , 是分配在内存的堆上的
struct 属于值类型 , 不能作为基类型 , 但是可以实现接口 , 是分配在内存的栈上的 .
new关键字的作用
运算符:创建对象实例
修饰符:在派生类定义一个重名的方法,隐藏掉基类方法
约束:泛型约束定义,约束可使用的泛型类型
int?和int有什么区别
int ?为可空类型,默认值可以是 null
int 默认值是 0
int? 是通过 int 装箱为引用类型实现
C#中值传递与引用传递的区别是什么?
值传递时,系统首先为被调用方法的形参分配内存空间,并将实参的值按位置一一对应地复制给形参,
此后,被调用方法中形参值得任何改变都不会影响到相应的实参;
引用传递时,系统不是将实参本身的值复制后传递给形参,而是将其引用值(即地址值)传递给形参,
因此,形参所引用的该地址上的变量与传递的实参相同,方法体内相应形参值得任何改变都将影响到作
为引用传递的实参。
简而言之,按值传递不是值参数是值类型,而是指形参变量会复制实参变量,也就是会在栈上多创建一
个相同的变量。而按引用传递则不会。可以通过 ref 和 out 来决定参数是否按照引用传递。
10.C#中参数传递 ref 与 out 的区别?
( 1 ) ref 指定的参数在函数调用时必须先初始化,而 out 不用
( 2 ) out 指定的参数在进入函数时会清空自己,因此必须在函数内部进行初始化赋值操作,而 ref 不用
总结: ref 可以把值传到方法里,也可以把值传到方法外; out 只可以把值传到方法外
注意: string 作为特殊的引用类型,其操作是与值类型看齐的,若要将方法内对形参赋值后的结果传递出来,需要加上ref 或 out 关键字。
C#中什么是装箱和拆箱?
装箱:把值类型转换成引用类型
拆箱:把引用类型转换成值类型
装箱:对值类型在堆中分配一个对象实例,并将该值复制到新的对象中。
( 1 )第一步:新分配托管堆内存 ( 大小为值类型实例大小加上一个方法表指针。
( 2 )第二步:将值类型的实例字段拷贝到新分配的内存中。
( 3 )第三步:返回托管堆中新分配对象的地址。这个地址就是一个指向对象的引用了。
拆箱:检查对象实例,确保它是给定值类型的一个装箱值。将该值从实例复制到值类型变量中。
在装箱时是不需要显式的类型转换的,不过拆箱需要显式的类型转换。
int i=0;
System.Object obj=i; // 这个过程就是装箱!就是将 i 装箱!
int j=(int)obj;// 这个过程 obj 拆箱!
C#实现多态的过程中 overload 重载 与override 重写的区别?
override 重写与 overload 重载的区别。
重载是方法的名称相同。参数或参数类型不同,进行多次重载以适应不同的需要
override 是进行基类中函数的重写。实现多态。
重载:是方法的名称相同,参数或参数类型不同;重载是面向过程的概念。
重写:是对基类中的虚方法进行重写。重写是面向对象的概念。 13.C# 中 static 关键字的作用?
对类有意义的字段和方法使用 static 关键字修饰,称为静态成员,通过类名加访问操作符 “.” 进行访问 ; 对
类的实例有意义的字段和方法不加 static 关键字,称为非静态成员或实例成员。
注 : 静态字段在内存中只有一个拷贝,非静态字段则是在每个实例对象中拥有一个拷贝。而方法无论是否
为静态,在内存中只会有一份拷贝,区别只是通过类名来访问还是通过实例名来访问。
C# 成员变量和成员函数前加static的作用?
它们被称为常成员变量和常成员函数,又称为类成员变量和类成员函数。
分别用来反映类的状态。
比如类成员变量可以用来统计类实例的数量,类成员函数
负责这种统计的动作。不用 new
C#中索引器的实现过程,是否只能根据数字进行索引,请描述一 下
C# 通过提供索引器,可以象处理数组一样处理对象。特别是属性,每一个元素都以一个 get 或 set 方法暴
露。索引器不单能索引数字(数组下标),还能索引一些 HASHMAP 的字符串,所以,通常来说, C# 中
类的索引器通常只有一个,就是 THIS ,但也可以有无数个,只要你的参数列表不同就可以了索引器和返
回值无关 , 索引器最大的好处是使代码看上去更自然,更符合实际的思考模式。
微软官方一个示例:
索引器允许类或结构的实例按照与数组相同的方式进行索引。 索引器类似于属性,不同之处在于它们的
访问器采用参数。 在下面的示例中,定义了一个泛型类( class SampleCollection ),并为其提供了简
单的 get 和 set 访问器 方法(作为分配和检索值的方法)。 Program 类为存储字符串创建了此类的一个
实例。
C#中 abstract class和interface有什么区别?
abstract class abstract 声明抽象类抽象方法,一个类中有抽象方法,那么这个类就是抽象类了。所谓的 抽象方法,就是不含主体(不提供实现方法),必须由继承者重写。因此,抽象类不可实例化,只能通 过继承被子类重写。
interface 声明接口,只提供一些方法规约,在 C#8 之前的版本中不提供任何实现,在 C#9 版本也可以支 持接口的实现;不能用public 、 abstract 等修饰,无字段、常量,无构造函数
两者区别:
1.interface 中不能有字段,而 abstract class 可以有 ; 2.interface 中不能有 public 等修饰符,而 abstract
class 可以有。 3.interface 可以实现多继承 。
C#中用sealed修饰的类有什么特点?
密封,不能继承。
字符串中string str=null和string str=””和string str=string.Empty的区别
string.Empty 相当于 “”,Empty 是一个静态只读的字段。 string str=”” , 初始化对象,并分配一个空字符串 的内存空间 string str=null, 初始化对象,不会分配内存空间
19.byte b = ‘a’; byte c = 1; byte d = ‘ab’; byte e = ‘啊’; byte g = 256; 这些变量有些错误是错在哪里?
本题考查的是数据类型能承载数据的大小。
1byte =8bit , 1 个汉字 =2 个 byte , 1 个英文 =1 个 byte=8bit
所以 bc 是对的, deg 是错的。 ‘a’ 是 char 类型, a 错误
java byte 取值范围是 -128127, 而 C# 里一个 byte 是 0255
string和StringBuilder的区别,两者性能的比较
都是引用类型,分配再堆上 StringBuilder默认容量是 16 ,可以允许扩充它所封装的字符串中字符的数量 . 每个 StringBuffer 对象都有 一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会 自动增加容量。
对于简单的字符串连接操作,在性能上 stringbuilder 不一定总是优于 strin 因为 stringbulider 对象的创建 也消耗大量的性能,在字符串连接比较少的情况下,过度滥用stringbuilder 会导致性能的浪费而非节约,只有大量无法预知次数的字符串操作才考虑stringbuilder 的使用。从最后分析可以看出如果是相对 较少的字符串拼接根本看不出太大差别。
Stringbulider 的使用,最好制定合适的容量值,否则优于默认值容量不足而频繁的进行内存分
什么是扩展方法?
一句话解释,扩展方法使你能够向现有类型 “ 添加 ” 方法,无需修改类型
条件:按扩展方法必须满足的条件, 1. 必须要静态类中的静态方法 2. 第一个参数的类型是要扩展的类型,并且需要添加this 关键字以标识其为扩展方法
建议:通常,只在不得已的情况下才实现扩展方法,并谨慎的实现
使用:不能通过类名调用,直接使用类型来调用
特性是什么?如何使用?
特性与属性是完全不相同的两个概念,只是在名称上比较相近。 Attribute 特性就是关联了一个目标对象的一段配置信息,本质上是一个类,其为目标元素提供关联附加信息,这段附加信息存储在dll 内的元数据,它本身没什么意义。运行期以反射的方式来获取附加信息
什么叫应用程序域(AppDomain)
一种边界,它由公共语言运行库围绕同一应用程序范围内创建的对象建立(即,从应用程序入口点开始,沿着对象激活的序列的任何位置)。
应用程序域有助于将在一个应用程序中创建的对象与在其他应用程序中创建的对象隔离,以使运行时行 为可以预知。
在一个单独的进程中可以存在多个应用程序域。应用程序域可以理解为一种轻量级进程。起到安全的作用。占用资源小。
byte a =255;a+=5;a的值是多少?
byte 的取值范围是 -2 的 8 次方至 2 的 8 次方 -1 , -256 至 258 , a+=1 时, a 的值时 0 , a+=5 时, a 的值是 0 ,所 以a+=5 时,值是
const和readonly有什么区别?
都可以标识一个常量。主要有以下区别:
1 、初始化位置不同。 const 必须在声明的同时赋值; readonly 即可以在声明处赋值 ;
2 、修饰对象不同。 const 即可以修饰类的字段,也可以修饰局部变量; readonly 只能修饰类的字段
3 、 const 是编译时常量,在编译时确定该值; readonly 是运行时常量,在运行时确定该值。
4 、 const 默认是静态的;而 readonly 如果设置成静态需要显示声明
5 、修饰引用类型时不同, const 只能修饰 string 或值为 null 的其他引用类型; readonly 可以是任何类型。
26.分析下面代码,a、b的值是多少?
分析:一个字母、数字占一个 byte ,一个中文占占两个 byte ,所以 a=8,b=5
27.Strings = new String(“xyz”);创建了几个String Object?
两个对象,一个是 “xyz”, 一个是指向 “xyz” 的引用对象 s 。
28.c#可否对内存直接操作
C# 在 unsafe 模式下可以使用指针对内存进行操作 , 但在托管模式下不可以使用指针, C#NET 默认不运行带指针的,需要设置下,选择项目右键-> 属性 -> 选择生成 ->“ 允许不安全代码 ” 打勾 -> 保存
29.什么是强类型,什么是弱类型?哪种更好些?为什么?
强类型是在编译的时候就确定类型的数据,在执行时类型不能更改,而弱类型在执行的时候才会确定类 型。没有好不好,二者各有好处,强类型安全,因为它事先已经确定好了,而且效率高。一般用于编译 型编程语言,如c++,java,c#,pascal等 , 弱类型相比而言不安全,在运行的时候容易出现错误,但它灵活, 多用于解释型编程语言,如javascript 等
30.Math.Round(11.5)等於多少? Math.Round(-11.5)等於多少?
Math.Round(11.5)=12
Math.Round(-11.5)=-12
31.&和&&的区别
相同点 &和 && 都可作逻辑与的运算符,表示逻辑与( and ),当运算符两边的表达式的结果都为 true 时,其结 果才为true ,否则,只要有一方为 false ,则结果为 false 。( ps :当要用到逻辑与的时候 & 是毫无意义, &本身就不是干这个的)
string strTmp = “a1某某某 “;
int a = System.Text.Encoding.Default.GetBytes(strTmp).Length;
int b = strTmp.Length; 不同点
if(loginUser!=null&&string.IsnullOrEmpty(loginUser.UserName))
&& 具有短路的功能,即如果第一个表达式为 false ,则不再计算第二个表达式,对于上面的表达式,当loginUser为 null 时,后面的表达式不会执行,所以不会出现 NullPointerException 如果将 && 改为 & ,则 会抛出NullPointerException 异常。( ps :所以说当要用到逻辑与的时候 & 是毫无意义的) & 是用作位运算的。 总结 &是位运算,返回结果是 int 类型 && 是逻辑运算,返回结果是 bool 类型
32.i++和++i有什么区别?
1.i++ 是先赋值,然后再自增; ++i 是先自增,后赋值。
2.i=0 , i++=0 , ++i=1 ; Console.WriteLine(++i==i++); 结果位 true
as和is的区别
as 在转换的同时判断兼容性,如果无法进行转换,返回位 null (没有产生新的对象), as 转换是否成功
判断的依据是是否位 null is 只是做类型兼容性判断,并不执行真正的类型转换,返回 true 或 false ,对象
为 null 也会返回 false 。
as 比 is 效率更高, as 只需要做一次类型兼容检查
谈谈final、finally的区别。
final :不能作为父类被继承。一个类不能声明是 final ,又声明为 abstract 。
finally :用于 try{}catch{}finally{} 结构,用于异常处理时执行任何清除操作。
简述C#成员修饰符
abstract: 指示该方法或属性没有实现。
const: 指定域或局部变量的值不能被改动。
event: 声明一个事件。
extern: 指示方法在外部实现。
override: 对由基类继承成员的新实现。
readonly: 指示一个域只能在声明时以及相同类的内部被赋值。
static: 指示一个成员属于类型本身 , 而不是属于特定的对象。
virtual: 指示一个方法或存取器的实现可以在继承类中被覆盖。
什么是匿名类,有什么好处?
不用定义、没有名字的类,使用一次便可丢弃。好处是简单、随意、临时的。
什么是虚函数?什么是抽象函数?
虚函数:没有实现的,可以由子类继承并重写的函数。
抽象函数:规定其非虚子类必须实现的函数,必须被重写。
什么是MVC模式
MVC(Model View Controller) 模型-视图-控制器
aspx 就是 View ,视图; Model : DataSet 、 Reader 、对象; Controller : cs 代码。
MVC 是典型的平行关系,没有说谁在上谁在下的关系,模型负责业务领域的事情,视图负责显示的事
情,控制器把数据读取出来填充模型后把模型交给视图去处理。而各种验证什么的应该是在模型里处理
了。它强制性的使应用程序的输入、处理和输出分开。 MVC 最大的好处是将逻辑和页面分离。 46. 能用 foreach 遍历访问的对象的要求
需要实现 IEnumerable 接口或声明 GetEnumerator 方法的类型。
什么是反射?
程序集包含模块,而模块又包括类型,类型下有成员,反射就是管理程序集,模块,类型的对象,它能
够动态的创建类型的实例,设置现有对象的类型或者获取现有对象的类型,能调用类型的方法和访问类
型的字段属性。它是在运行时创建和使用类型实例。
ORM中的延迟加载与直接加载有什么异同?
延迟加载( Lazy Loading )只在真正需要进行数据操作的时候再进行加载数据,可以减少不必要的开销。
简述Func与Action的区别?
Func 是有返回值的委托, Action 是没有返回值的委托。
ref: https://blog.csdn.net/bt5190/article/details/118144811
x86_64 asm
Intel x86 CPU部分寄存器介绍
EAX:一般用作累加器,函数的返回值
EBX:一般用作基址寄存器(Base)
ECX:一般用来计数(Count)
EDX:一般用来存放数据(Data)
ESP:一般用作堆栈栈定指针(Stack Pointer)
EBP:一般用作堆栈栈底指针(Base Pointer)
ESI:一般用作源变址(Source Index)
EDI:一般用作目标变址(Destinatin Index)
EIP : 记录即将执行下一条指令的地址
Intel x64 CPU部分寄存器介绍
RAX:一般用作累加器,函数的返回值
RBX:一般用作基址寄存器(Base)
RCX:一般用来计数(Count)
RDX:一般用来存放数据(Data),函数调用的第三个参数
RSP:一般用作堆栈指针(Stack Pointer)
RBP:一般用作基址指针(Base Pointer)
RSI:一般用作源变址(Source Index),函数调用的第二个参数
RDI:一般用作目标变址(Destinatin Index),函数调用的第一个参数
RIP : 记录即将执行下一条指令的地址
部分Intel汇编指令介绍
mov eax, 1 ; 给eax寄存器赋值1
add eax, 3 ; 取出eax中的值加上3之后将结果保存至eax
sub eax, 4 ; 取出eax中的值减上4之后将结果保存至eax
push eax ; 将eax中的值压入堆栈中
push 2 ; 将2压入堆栈中
pop ecx ; 将栈顶里的值弹给ecx寄存器
call 0x1234 ; 等价于 push call指令的下一条指令地址,然后mov eip, 0x1234
ret ; 等价与 pop eip
jmp 0x1234 ; 等价于 mov eip, 0x1234
nop ; 空指令,等价于 add eip, 1
函数调用约定
32位程序函数调用: 一般从右至左依次将参数压入堆栈
1 | |
64位程序函数调用: 从右至左依次传递参数,优先采用寄存器进行传参,当参数大于6个,后续参数采用堆栈进行传参. 寄存器顺序是:
rdi,rsi,rdx, rcx, r8, r9
1 | |
Call指令跳转地址计算方式
call指令为E8
比如:
1 | |
这个机器码该怎么反编译:
e8 为 call
c3 为 ret
12 34 56 78小端存储还原值为 0x78563412
则跳转的地址为:
target - next_addr = 0x78563412
target = 0x1239 + 0x78563412 = 0x78564651
反编译为:
1 | |
Armv7 asm
寄存器
r0
r1
r2
r3
r4
r5
r6
r7
r8
r9
r10
r11
r12
sp
pc
指令
bl 相当于x86 call
b 相当于x86 return
add
sub
ldr
mov
beq
cmp
bne
str
STR{条件} 源寄存器,<存储器地址>
STR指令用亍从源寄存器中将一个32位的字数据传送到存储器中。该指令在程序设计中比较常
用,寻址方式灵活多样,使用方式可参考指令LDR。
指令示例:
STR R0,[R1],#8 ;将R0中的字数据写入以R1为地址的存储器中,并将新地址R1+8写入R1。
STR R0,[R1,#8] ;将R0中的字数据写入以R1+8为地址的存储器中。”
str r1, [r0] ;将r1寄存器的值,传送到地址值为r0的(存储器)内存中
堆栈结构
当一个函数调用使用少量参数(ARM上是少于等于4个)时,参数是通过寄存器进行传值(ARM上是通过r0,r1,r2,r3),而当参数多于4个时,会将多出的参数压入栈中进行传递(其实在函数调用过程中也会把r0,r1,r2,r3传递的参数压入栈)
工具
GDB
部分gdb调试命令
si ;单步调试,遇到call指令,跟踪进入
b *0x1234 ; 在0x1234地址处下断点
i b ; 查看所有断点
i r ; 查看寄存器
p $eax ; 查看eax寄存器的值
lay asm ; 打开汇编界面
c ; 一直运行,直到遇到断点停下
start ; 默认在程序入口下段点,在程序入口停下
run ; 每输入一次,重新运行程序
x /40wx $eax ; 查看eax寄存器指向的内存中的内容
x /20gx 0x1234 ; 查看内存地址0x1234中的内容
q 退出gdb
finish 结束该函数
部分gdb pwndbg插件命令
vmmap ; 查看内存页布局
stack ; 查看堆栈内容
heap ; 查看堆的chunk布局
bin ; 查看堆中的bin
parseheap ; 解析堆布局
IDA
常用快捷键
a:将数据转换为字符串
f5:一键反编译
shift+f12:可以打开string窗口
ctrl+s:选择某个数据段,直接进行跳转
x:对着某个函数、变量按该快捷键,可以查看它的交叉引用
n:更改变量的名称
y:更改变量的类型
g:直接跳转到某个地址
ctrl+shift+w:拍摄IDA快照
u:undefine,取消定义函数、代码、数据的定义
b:按下B键转换为二进制也是同理。
c: 将数据段转化成代码
h:在数字上按下H键或者右键进行选择,可以将数字转化为十进制:
Ghidra
Ghidra是一个软件逆向工程(SRE)框架,包括一套功能齐全的高端软件分析工具,使用户能够在各种平台上分析编译后的代码,包括Windows、Mac OS和Linux。功能包括反汇编,汇编,反编译,绘图和脚本,以及数百个其他功能。Ghidra支持各种处理器指令集和可执行格式,可以在用户交互模式和自动模式下运行。用户还可以使用公开的API开发自己的Ghidra插件和脚本。
Antsword
中国蚁剑是一款开源的跨平台网站管理工具,它主要面向于合法授权的渗透测试安全人员以及进行常规操作的网站管理员。在CTF中,主要用于连接web shell,且使用了编/解码器进行流量混淆可绕过WAF,并且有多款实用插件。
github: https://github.com/AntSwordProject/antSword
Arachni
Arachni是一个能够满足很多使用场景的通用的安全扫描框架,范围覆盖非常广,既包括小到一个命令行指令的扫描,又包括高性能的网格扫描、脚本认证审计、多用户多web合作平台。此外,它简单的REST API使集成变得轻而易举。
Sqlmap
sqlmap是一个开源,跨平台的自动化SQL注入工具,目前支持大多数主流数据库有MySQL,Oracle, PostgreSQL, Microsoft SQL Server, Microsoft Access, IBM DB2, SQLite等
特性:
- sqlmap是一款开源免费的漏洞检查、利用工具.
- 可以检测页面中get,post参数,cookie,http头等.
- 可以实现数据榨取
- 可以实现文件系统的访问
- 可以实现操作命令的执行
- 还可以对xss漏洞进行检测
- 基于布尔的盲注检测 (如果一个url的地址为xxxx.php?id=1,那么我们可以尝试下的加上 and 1=1(和没加and1=1结果保持一致) 和 and 1=2(和不加and1=2结果不一致),则我们基本可以确定是存在布尔注入的. )
- 基于时间的盲注检测(和基于布尔的检测有些类似.通过mysql的 sleep(int)) 来观察浏览器的响应是否等待了你设定的那个值 如果等待了,则表示执行了sleep,则基本确定是存在sql注入的
- 基于错误的检测 (组合查询语句,看是否报错(在服务器没有抑制报错信息的前提下),如果报错 则证明我们组合的查询语句特定的字符被应用了,如果不报错,则我们输入的特殊字符很可能被服务器给过滤掉(也可能是抑制了错误输出.))
- 基于union联合查询的检测(适用于如果某个web项目对查询结果只展示一条而我们需要多条的时候 则使用union联合查询搭配concat还进行获取更多的信息)
- 基于堆叠查询的检测(首先看服务器支不支持多语句查询,一般服务器sql语句都是写死的,某些特定的地方用占位符来接受用户输入的变量,这样即使我们加and 也只能执行select(也不一定select,主要看应用场景,总之就是服务端写了什么,你就能执行什么)查询语句,如果能插入分号;则我们后面可以自己组合update,insert,delete等语句来进行进一步操作)
ref:
http://t.zoukankan.com/php09-p-10404560.html
https://blog.csdn.net/talentac/article/details/123050653
Xray
github: https://github.com/chaitin/xray
xray 是一款功能强大的安全评估工具,由多名经验丰富的一线安全从业者呕心打造而成,主要特性有:
- 检测速度快。发包速度快; 漏洞检测算法高效。
- 支持范围广。大至 OWASP Top 10 通用漏洞检测,小至各种 CMS 框架 POC,均可以支持。
- 代码质量高。编写代码的人员素质高, 通过 Code Review、单元测试、集成测试等多层验证来提高代码可靠性。
- 高级可定制。通过配置文件暴露了引擎的各种参数,通过修改配置文件可以极大的客制化功能。
- 安全无威胁。xray 定位为一款安全辅助评估工具,而不是攻击工具,内置的所有 payload 和 poc 均为无害化检查。
目前支持的漏洞检测类型包括:
- XSS漏洞检测 (key: xss)
- SQL 注入检测 (key: sqldet)
- 命令/代码注入检测 (key: cmd-injection)
- 目录枚举 (key: dirscan)
- 路径穿越检测 (key: path-traversal)
- XML 实体注入检测 (key: xxe)
- 文件上传检测 (key: upload)
- 弱口令检测 (key: brute-force)
- jsonp 检测 (key: jsonp)
- ssrf 检测 (key: ssrf)
- 基线检查 (key: baseline)
- 任意跳转检测 (key: redirect)
- CRLF 注入 (key: crlf-injection)
- Struts2 系列漏洞检测 (高级版,key: struts)
- Thinkphp系列漏洞检测 (高级版,key: thinkphp)
- POC 框架 (key: phantasm)
其中 POC 框架默认内置 Github 上贡献的 poc,用户也可以根据需要自行构建 poc 并运行。
Angr
angr是一个基于python的框架支持多处理器架构的二进制分析工具包,它具有对二进制程序动态符号化执行以及多种静态分析的能力。官网,安装也非常简单,直接docker拉取或者pip install angr就能一键安装。
装载机
1 | |
加载的对象
CLE loader(cle.Loader)表示整个加载的二进制对象集合,加载并映射到单个内存空间。每个二进制对象都由一个可以处理其文件类型(cle.Backend)的加载器后端加载。例如,cle.ELF用于加载ELF二进制文件。
内存中的对象也不会与任何加载的二进制文件相对应。例如,用于提供线程本地存储支持的对象,以及用于提供未解析符号的externs对象。
您可以获得CLE已加载的对象的完整列表loader.all_objects,以及几个更有针对性的分类:
1 | |
您可以直接与这些对象进行交互以从中提取元数据:
1 | |
符号和重新定位
还可以在使用CLE时使用符号。符号是可执行格式世界中的基本概念,有效地将名称映射到地址。
从CLE获取符号的最简单方法是使用loader.find_symbol,它接受名称或地址并返回Symbol对象。
1 | |
符号上最有用的属性是其名称,所有者和地址,但符号的“地址”可能不明确。Symbol对象有三种报告其地址的方式:
.rebased_addr是它在所有地址空间中的地址。这是打印输出中显示的内容。.linked_addr是它相对于二进制的预链接基础的地址。.relative_addr是它相对于对象库的地址。这在文献(特别是Windows文献)中称为RVA(相对虚拟地址)。
1 | |
除了提供调试信息之外,符号还支持动态链接的概念。libc提供函数符号作为导出,主二进制文件依赖于它。如果我们要求CLE直接从主对象给我们一个函数符号,它会告诉我们这是一个导入符号。导入符号没有与之关联的有意义的地址,但它们确实提供了用于解析它们的符号的引用,如.resolvedby。
1 | |
导入和导出之间的链接在内存中注册的具体方式由另一个名为relocations的概念处理。重定位也就是“当您使用导出符号匹配*[import]时,请将导出地址写入[location],格式为[format]*。” 我们可以看到对象(作为Relocation实例)的完整重定位列表obj.relocs,或者把符号名称到Relocation as的映射作为obj.imports。没有相应的导出符号列表。
可以访问重定位的相应导入符号.symbol。重定位将写入的地址,可用于Symbol的任何地址标识符访问,并且您也可以获取对请求重定位的对象的引用.owner_obj。
1 | |
如果导入无法解析为任何导出,例如,因为找不到共享库,CLE将自动更新externs对象(loader.extern_obj)以声明它将符号作为导出。
加载选项
如果要加载某些内容angr.Project并且想要将选项传递给cle.LoaderProject隐式创建的实例,则只需将关键字参数直接传递给Project构造函数,它就会传递给CLE。如果您想知道可能作为选项传递的所有内容,但我们将在此处介绍一些重要且经常使用的选项。
1 | |
基本选项
我们已经讨论过auto_load_libs- 它启用或禁用CLE尝试自动解析共享库依赖项,默认情况下处于启用状态。此外,还有相反的情况,except_missing_libs如果设置为true,则只要二进制文件具有无法解析的共享库依赖项,就会引发异常。
您可以传递一个字符串列表,force_load_libs列出的任何内容都将被视为一个未解析的共享库依赖项,或者您可以传递一个字符串列表skip_libs以防止该名称的任何库被解析为依赖项。此外,您可以custom_ld_path在任何默认值之前传递一个字符串列表(或单个字符串),它将用作共享库的附加搜索路径:与加载的程序相同的目录,当前工作目录和你的系统库。
额外选项
如果要指定仅适用于特定二进制对象的某些选项,CLE也会允许您这样做。参数main_ops和``lib_opts通过选择词典来完成。main_opts是从选项名称到选项值lib_opts的映射,同时是从库名称到字典映射选项名称到选项值的映射。
您可以使用的选项从后端各不相同,但一些常见的选项是:
backend- 使用哪个后端,作为类或名称custom_base_addr- 要使用的基地址custom_entry_point- 使用的入口点custom_arch- 要使用的体系结构的名称
例如
1 | |
后端
CLE目前有后端静态加载ELF,PE,CGC,Mach-O和ELF核心转储文件,以及使用IDA加载二进制文件并将文件加载到平面地址空间。在大多数情况下,CLE会自动检测正确的后端,所以你不需要指定你正在使用哪个后端,除非你做了一些非常奇怪的事情。
如上所述,您可以通过在其选项字典中包含一个键来强制CLE使用特定的后端作为对象。某些后端无法自动检测要使用的架构,并且必须具有custom_arch指定的架构。密钥不需要匹配任何体系结构列表; angr将确定您所指的架构的任何公共标识符。
要引用后端,请使用此表中的名称:
| backend name | description | requires custom_arch? |
|---|---|---|
| elf | 基于PyELFTools的ELF文件的静态加载程序 | no |
| pe | 基于PEFile的PE文件静态加载器 | no |
| mach-o | Mach-O文件的静态加载程序。不支持动态链接或变基。 | no |
| cgc | Cyber Grand Challenge二进制文件的静态加载程序 | no |
| backedcgc | GC二进制文件的静态加载程序,允许指定内存和寄存器 | no |
| elfcore | 用于ELF核心转储的静态加载程序 | no |
| ida | 启动IDA实例来解析文件 | yes |
| blob | 将文件作为平面镜像加载到内存中 | yes |
符号函数摘要
默认情况下,Project尝试使用称为SimProcedures的符号摘要替换对库函数的外部调用- 实际上只是模仿库函数对状态的影响的python函数。我们已经实现了一大堆 SimProcedures 功能。这些内置过程在angr.SIM_PROCEDURES字典中可用,它是两层的,首先在包名称(libc,posix,win32,stubs)上植入,然后在库函数的名称上植入。执行SimProcedure而不是从系统加载的实际库函数使得分析更容易处理,代价是一些潜在的不准确性。
1 | |
如果没有针对给定函数的摘要:
- 如果
auto_load_libs是True(这是默认值),则执行真正的库函数。根据实际功能,这可能是您想要的,也可能不是。例如,某些libc的函数分析非常复杂,并且很可能会导致尝试执行它们的路径的状态数量激增。 - 如果
auto_load_libs是False,则外部函数未解析,Project将其解析为通用的“存根”SimProcedure调用ReturnUnconstrained。它的名字就是这样:它每次调用时都会返回一个唯一的无约束符号值。 - 如果
use_sim_procedures(这是一个参数angr.Project,而不是cle.Loader)是False(True默认情况下),那么只有extern对象提供的符号将被SimProcedures替换,它们将被一个存根替换ReturnUnconstrained,它只会返回一个符号值。 - 您可以指定要排除的特定符号,以使用以下参数替换为SimProcedures
angr.Project:exclude_sim_procedures_list和exclude_sim_procedures_func。 - 查看
angr.Project._register_object确切算法的代码。
Hooking
angr用python替换库代码的机制称为挂钩,你也可以这样做!在执行模拟时,每个步骤都会检查当前地址是否已挂钩,如果是,则运行挂钩而不是该地址处的二进制代码。该API,让你做到这一点是proj.hook(addr, hook),这里hook是一个SimProcedure实例。您可以使用和管理项目的钩子.is_hooked,希望不需要解释。.unhook``.hooked_by
有一个用于挂钩地址的备用API,通过使用proj.hook(addr)函数装饰器,您可以指定自己的函数作为钩子使用。如果执行此操作,还可以选择指定length关键字参数,以使执行在挂钩完成后向前跳转一些字节数。
1 | |
此外,您可以使用proj.hook_symbol(name, hook)符号名称作为第一个参数来挂钩符号所在的地址。一个非常重要的用法是扩展angr的内置库SimProcedures的行为。由于这些库函数只是类,因此可以对它们进行子类化,覆盖它们的行为,然后在钩子中使用子类。
您还可以在使用CLE时使用符号。符号是可执行格式世界中的基本概念,有效地将名称映射到地址。
从CLE获取符号的最简单方法是使用loader.find_symbol,它接受名称或地址并返回Symbol对象。
CFG (控制流程图)
angr提供2种方式访问CFG,CFGFast和CFGEmulated。
CFGFast采用静态方式生成CFG,会受限于某些CFG只能运行时产生。CFGEmulated采用符号执行生成CFG。而可能由于符号执行路径不全的问题可能造成CFG一些缺失。
- 首先计算CFGFast
说明:angr中CFG()是CFGFast()的子类,也就是在CFGFast()基础上的一个包装。

这里我们通过angr-utils将cfg绘画出来,看起来更直观:
因此总结来说,angr计算CFG的过程就是:模拟执行每个基本块,并判断该基本块下一步会走向哪个基本块,从而建立cfg的边关系。然而存在一些困难:一个基本块在不同的上下文中会有不同的表现形式。举例来说,一个函数返回时的基本块(即上面的func()函数),对于不同的调用者而言该基本块的下一跳的地址是不一样的。因此上下文调用关系的保留情况对于CFG构建至关重要。angr中即是通过context_sensitivity_level参数来确定在调用栈中保留多少个函数
ref: http://t.zoukankan.com/0xHack-p-9400900.html
ref: https://blog.csdn.net/sp5627896/article/details/83067907
AFL
AFL-Fuzz介绍
AFL(American Fuzzy Lop)是由Google安全工程师Michał Zalewski开发的一款开源fuzzing测试工具。
- 其可以高效地对二进制程序进行fuzzing,挖掘可能存在的内存安全漏洞,如栈溢出、堆溢出、UAF、double free等。
- 由于需要在相关代码处插桩,因此AFL主要用于对开源软件进行测试。
- 配合QEMU等工具,也可对闭源二进制代码进行fuzzing,但执行效率会受到影响。
工作原理:通过对源码进行重新编译时进行插桩(简称编译时插桩)的方式利用自动产生测试用例来探索二进制程序内部新的执行路径。另一种是直接对没有源码的二进制程序进行测试,但需要QEMU的支持。
它的工作流程大致如下:
- 将用户提供的初始测试用例加载到队列中
- 从队列中获取下一个输入文件
- 尝试将测试用例调整到不会影响程序行为的最小大小
- 使用均衡的经过充分研究过的各种传统模糊测试策略反复的变异文件
- 如果任何生成的突变导致记录了一个新的状态转换,将变异的输出作为新的加入到队列中
- 回到步骤2开始重复操作发现的测试用例也会定期选出部分消除,用更新的更高覆盖率的用例所取代,并执行几个其他插桩驱动的工作量最小化步骤。
AFL变异策略
确定性变异
- 比特翻转(bitflip):按位翻转,1变为0,0变为1.这一阶段还会按照不同的长度和步长进行多种不同的翻转,每次翻转1/2/4/8/16/32 bit,依次进行。
- 算术运算(arithmetic):整数加/减算术运算。跟bitflip类似,arithmetic根据目标大小的不同,也分为了多个子阶段,依次对8/16/32 bit进行加减运算。
- 特殊值替换(interest):把一些特殊内容替换到原文件中。同样每次对8/16/32 bit进行替换。所谓的特殊内容是AFL预设的一些比较特殊的数,比如可能造成溢出的数。
- 字典值(dictionary):把自动生成或用户提供的字典值替换或插入到原测试用例中。
随机变异
- havoc大破坏:对文件进行大量破坏,此阶段会对原文件进行大量随机变异。包括随机翻转、加减、替换和删除等操作。
- 文件拼接splice:此阶段会将两个文件拼接起来得到一个新的文件,并对这个新文件继续执行havoc变异。
ref: https://zhuanlan.zhihu.com/p/524552737
ref: https://baijiahao.baidu.com/s?id=1660936764080017733&wfr=spider&for=pc
Github项目
Pwn Waf
ctf awd 流量抓取工具
https://github.com/I0gan/pwn_waf
该WAF拥有四种模式,流量抓取模式,通防模式,单目标流量转发模式,多目标流量转发模式,代码轻巧简单,可以根据自己需求二次开发,waf配置简单,没有依赖,日志格式清晰明了,拥有16进制字符串payload,更方便编写反打EXP。
Awd Script
ctf awd 批量攻击脚本
https://github.com/i0gan/awd_script
AWD批量攻击脚本(Web/Pwn通用),通过bash编写,远程信息采用参数传入exp,通过多进程方式实现同时攻打,阻塞超时自动结束进程。
Gsky
自研高性能游戏服务器库
https://github.com/pwnsky/gsky
为了便于更快速开发高性能游戏服务器,特意基于lgx web服务器框架,二次开发且封装为一个服务器库。 gsky是一个基于epoll 边缘触发架构的高性能游戏服务器库,采用更快速的pp (pwnsky protocol)二进制加密双向协议进行传输数据,服务端支持异步消息推送,日志打印与日志文件写入等,让使用者更专注与游戏逻辑开发。
CTF Avoid Py
CTF网络安全大赛中很实用的防止PY工具,在PWN这里一抓一个准!
https://github.com/pwnsky/ctf-avoid-py
CTF大赛中很实用的防止PY工具,国内的PY现象日渐泛滥,在这种趋势下,想要赛选出真正有实力的选手还得看举办方的一个比赛规则的规定,也是举办方与参赛选手的一种对抗。再此呢,我开发了skyaf工具,在CTF PWN中十抓九准!曾经实践于2021安洵杯所有pwn题中,大家有兴趣的话,可以看一下当时的流量抓取情况,这里不提供审计结果报告,只提供原始数据。
PP-SDK
Gsky客户端SDK
https://github.com/pwnsky/GskyClient
pp 协议,全称为 pwnsky protocol, 是一款吸收http部分特性的一款二进制传输协议,主要用于游戏长连接交互协议,目前基于tcp来实现。
该协议头部只占16字节,相对与http更小,由于协议字段都在固定位置,解析起来更快速。
pp协议中定义有状态码,数据类型,数据长度,请求路由。
采用pe (pwnsky encryption)进行数据加密,由服务端随机生成8字节密钥返回给客户端,客户端接收到之后,在断开之前传输数据都采用该密钥进行加解密。
Squick
https://github.com/pwnsky/Squick
Squick是采用C++开发的元宇宙、MMO游戏服务器快速开发方案,支持局部热重载、插件化开发、与客户端实现帧同步,可快速开发元宇宙、MMO游戏项目等。
特性
- 采用动态连链接库方式动态加载插件,开发拓展插件,让开发服务器变成开发插件
- 插件化管理方式,可对插件进行加载与卸载实现不用关掉程序,就可以实现热重载功能。
- 遵守谷歌C++编程规范
- 事件和属性驱动,让开发变得更简单
- Excel文档配置
- 日志捕获系统
- 支持部分不用停服即可热更,动态实现替换插件
- 默认拥有服务器插件:代理服务器、世界服务器、导航系统、数据库服务器、中心服务器、登录服务器
- 分布式服务、各服务之间通过网络来进行沟通,可通过分布式+集群方式减轻服务器压力
- 拥有协程异步、事件与属性驱动,提升开发效率
- Lua热更新、热重载、lua脚本可管理c++插件以及lua插件。通过lua可以动态热更新c++层面的插件(.so文件),实现lua热更以及c++ native层的热热更新。
- 采用Redis + Mysql作为数据库,通过数据库服务器,让数据灵活存储。
Uquick
https://github.com/pwnsky/Uquick
Unity3d元宇宙和MMO游戏的快速开发方案,支持冷更新+热更新、微信登录、帧同步、状态同步。
特性
使Unity开发的游戏支持热更新的解决方案
仅需下载并打开框架,就可以开始制作可热更新的游戏,无额外硬性要求。
框架进行了集成以及完善的封装,无需关注热更原理即可使用强大的功能。
动画系统同步
位置、旋转同步
场景对象基本信息同步
代理
正向代理
在靶机服务器上运行代理程序监听端口,用自己的电脑直接连接即可。这种情况是靶机能够开放其他端口出来,用户能够访问到靶机上监听的端口。
工具:
goproxy、ew
反向代理
在自己的电脑或vps上用代理程序监听端口,然后再在靶机服务器上运行代理客户端来连接代理监听的端口,即可实现用户通过该模式用到靶机服务器上的网络环境。
这种情况是靶机不能够开放其他端口出来,但靶机能够访问vps或者用户电脑。
工具:
goproxy、ew
隧道
采用隧道连接程序,访问网站的特定URL,服务端运行了特定的代理代码,让http协议转化成一个原生socket,且不断开连接,之后走的代理就根据该socket来传输数据。
这种情况是靶机不能够开放其他端口出来,靶机也不能能够访问vps或者用户电脑,但选手能够访问到靶机网站。
工具:NeoreGeorg
端口转发
将一个绑定的端口在不修改任何源服务的情况下,再次将该服务端口绑定在另一个端口上,比如我内网服务器1开启了个web服务,绑定端口为80,内网服务器2能够访问该内网服务器1且公网也能够访问内网服务器1,我们再不修改内网服务器1的服务情况下,将其服务绑定在内网服务器2,这样外网就能够访问到该服务了,每一次连接内网服务器2的时候,它会主动去与内网服务器1进行连接,从而将内网服务器2的数据经过端口转发给了内网服务器1。
内网穿透
内网穿透是将内网服务经过两层代理将其服务公布在公网上的一种手段,让其他能够访问公网的用户也能够访问到内网服务。
工具:
goproxy、ew
N级代理搭建
在内网中,出现了多个层级的靶机,我们就需要搭建N级代理了,让我们的代理呈现出一种链式的,goproxy也可以在该代理链中随意切换代理到任意节点,十分方便。
工具:
goproxy、ew
分析过的CVE
这里就说一下自己以前分析过的CVE吧,其实在打CTF比赛中,也遇到很多CVE,比如malloc函数的cve、CJson、v8的CVE等等,然后根据poc结合环境来利用的。
路由器
CVE-2018-18708
CVE-2018-18708,多款Tenda产品中的httpd存在缓冲区溢出漏洞。攻击者可利用该漏洞造成拒绝服务(覆盖函数的返回地址)。以下产品和版本受到影响:Tenda AC7 V15.03.06.44_CN版本;AC9 V15.03.05.19(6318)_CN版本;AC10 V15.03.06.23_CN版本;AC15 V15.03.05.19_CN版本;AC18 V15.03.05.19(6318)_CN版本。
漏洞点
1 | |
sub_2E128 -> sub_2E6F4 ->sub_41F18 -> formSetMacFilterCfg -> sub_BD758 -> sub_BDA1C -> sub_BE73C
那么现在我们就可以访问“/goform/setMacFilterCfg”时会进入formSetMacfiltercfg函数,传入类似与json的数据进行解析,则会将value值传入漏洞触发点。
exp
1 | |
log输出如下
1 | |
发现不能运行到我们的位置,进行再调试调试看看是那块没有绕过。重新下断电在formSetMacFilterCfg函数,偏移为: 000BCB9C
发现能够调用到formSetMacFilterCfg函数,但没法继续调用下一个函数,再来分析分析还有什么条件没有绕过。
1 | |
执行到GetValue的时候, 会出现http响应错误,然而该函数是调用lib的,只能先分析一下lib。
通过分析lib中的GetValue函数,会议cookie值检测,需要包含password等字段,内容随便伪造。
poc如下
触发poc
1 | |
漏洞触发如下
1 | |
这时发现,已经修改了PC寄存器,实现了劫持。
漏洞利用
接下来就计算偏移找system函数了。
1 | |
堆栈数据如上,由于是如下进行弹堆栈的,需要再填充(0x238 - 0x1d4)个字节才可以修改pc寄存器,实现劫持。
1 | |
重新修改poc
1 | |
运行如下,那么就可以知道在哪可以实现修改pc寄存器了。
1 | |
由于程序没有开启alsr与pie那么glibc中的基址是固定的。
直接算获取system地址。vmmap获取glibc基址为0xf659b000
在libc中找到system函数偏移
1 | |
这里记得检查下CPSR寄存器的T位,因为栈上内容弹出到PC寄存器时,其最低有效位(LSB)将被写入CPSR寄存器的T位,而PC本身的LSB被设置为0。如果T位值为1,需要在地址上加一还原。
1 | |
寻找gadgets
gadget1
用于修改r3寄存器
1 | |
gadget2
1 | |
payload结构为[offset, gadget1, system_addr, gadget2, cmd]
先将system函数地址储存在r3寄存器中,执行到gadget2将sp的值赋给r0,也就是将sp作为system的参数,而这时sp指向的是cmd。
poc
1 | |
修改url 为docker所转发的端口,现在试试在docker上是否已经创建test文件
1 | |
可以看到已经创建了test文件。
那么如何实现交互呢?就采用bash下来反弹sehll 吧。
先在自己的服务器上使用nc来监听。
1 | |
在poc中的命令填写为
1 | |
192.168.43.13是我物理机的ip,4444是我nc监听的端口。
现在poc为
1 | |
在服务器上开启监听:
1 | |
火狐浏览器
CVE-2016-9079
火狐浏览器上暴露的一个 JavaScript漏洞,而且已经被用于攻击 Tor 用户。该漏洞是一个存在于SVG Animation模块中的释放后UAF漏洞,当用户使用Firefox浏览包含恶意Javascript和SVG代码的页面时,会允许攻击者在用户的机器上远程执行代码。受该漏洞影响的平台包括Windows,Mac OS以及Linux。
攻击者通过堆喷射技术在内存中大量分配填充预定义的指令从而绕过地址空间随机化(ASLR)
需要通过msfvnom来生成python的payload,在通过一个脚本,将其转换为js代码,浏览器直接访问页面即可RCE。
CVE-2016-1960
是火狐浏览器上的一个漏洞,HTML5 字符串解析器中的 nsHtml5TreeBuilder 类中的整型溢出允许攻击者通过利用对结束标签的错误处理来任意代码执行。
V8
Linux 提权
CVE-2019-14287
它是一个提权cve,利用条件是首先该用户是在/etc/sudoer中配置得有sudo权限的,在黑客不知道用户密码的情况下,能够提权为root。
条件:
用户需要拥有sudo权限,并允许用户使用任意用户ID来运行命令。意味着用户的sudoer项在Runas规范中定义了特殊的ALL值。
如果sudoer策略允许的话,sudo支持由用户指定的用户名或用户ID来运行命令。比如说,下列sudoer项允许我们以任意用户的身份来运行id命令,因为在Runas规范中它包含了ALL关键字。
1 | |
除了以任意有效用户的身份运行id命令之外,我们还能够以任意用户ID来运行该命令,此时需要使用#uid语句:
1 | |
该命令将返回“1234”。但是,sudo可以使用setresuid(2)和setreuid(2)这两个系统调用来在命令运行之前修改用户ID,并将用户ID修改为-1(或未签名的等价用户ID-4294967295):
1 | |
或
1 | |
上述命令运行之后,将返回“0”。这是因为sudo命令本身已经在以用户ID“0”运行了,所以当sudo尝试将用户ID修改为“-1”时,不会发生任何变化。
但是,sudo日志条目中记录下的命令运行用户的ID为“4294967295”,而并非root用户(或用户ID为“0”),除此之外,因为用户ID是通过-u选项指定的,并且不会在密码数据库中存储,所以PAM会话模块也不会运行。
如果sudoer条目允许用户以任意用户身份运行命令(非root),那么攻击者就可以利用该漏洞来绕过这种限制了。比如说,我们有下列sudoer条目:
1 | |
用户bob能够以除了root之外的其他任意用户身份来运行命令vi,但由于该漏洞的存在,bob实际上能够通过下列命令来以root权限运行vi命令,并绕过目标系统中的安全策略:
1 | |
只有当包含了ALL关键词的sudoer条目存在于Runas规范中时,该漏洞才存在。比如说,如果规范中包含下列sudoer条目的话,目标系统是不会受到该漏洞影响的:
1 | |
在上述例子中,alice只能够以root权限运行id命令,任何以不同身份用户运行命令的尝试都将被拒绝。
CVE-2021-3156
CVE-2021-3156 漏洞主要成因在于sudo中存在一个基于堆的缓冲区溢出漏洞,当在类Unix的操作系统上执行命令时,非root用户可以使用sudo命令来以root用户身份执行命令。由于sudo错误地在参数中转义了反斜杠导致堆缓冲区溢出,从而允许任何本地用户(无论是否在sudoers文件中)获得root权限,无需进行身份验证,且攻击者不需要知道用户密码
crash
1 | |
跟进main函数,然后会执行policy_check函数
1 | |
会发现程序执行流走向了plugin->u.policy->check_policy(argc, argv, env_add, command_info,argv_out, user_env_out);
1 | |
函数非常简短,基本就是设置一些变量,然后就去调用了sudoers_policy_main函数,继续跟进到sudoers_policy_main函数中:
1 | |
先是传了一些参数,然后调用set_cmnd,我在gdb调的时候用的命令是sudoedit -s ‘\’ aaaaaaaa
漏洞点
看看set_cmnd做了什么
1 | |
同样也是省略了一些不需要分析的代码
走到这里,我们终于来到了溢出点,我们输入的参数就是在这里被存进堆中,我们将这段代码切割成小的代码片来分析它的意图
首先是申请内存部分:
1 | |
这里计算了每一个参数的长度,然后把他们加到一起,得到一个size,然后malloc(size),这里的意图很明显,就是算一下想要装下所有的参数需要多大的空间,然后申请出来,指针给到user_args
接下来是拷贝部分:
1 | |
这里就是漏洞所在,它把每个参数取出来,让from指针指向参数内容,to指针则指向堆内存,然后判断如果是反斜杠+非空格字符这种结构,就只拷贝后面这个字符,不拷贝反斜杠。参数与参数之间是用空格分割。
这里我们先仔细关注一下NewArgv是怎么保存的我们的参数。
触发漏洞的路径可以总结为:
sudo.c : main
sudo.c : policy_check
policy.c : sudoerrs_policy_check
sudoers.c : sudoers_policy_main
sudoers.c : set_cmnd
sudoers.c : 859
利用手法分析
本漏洞利用手法有一定的堆布局难度,是通过堆溢出覆盖nss_load_library函数加载so的时候需要用到的结构体service_user,覆盖此结构体中的so名字符串,这样就可以让程序加载我们指定的so文件,从而完成任意代码执行的。
我们要做的事情有两个:
1.搞清楚nss_load_library的函数调用流程和相关的数据结构机制
2.setlocale 如何通过环境变量LC_* 进行堆布局
漏洞利用关键代码片段:
1 | |
ni为堆上的service_user 结构体,当 ni->library->lib_handle 为NULL 时,就会调用__libc_dlopen 进行 so 装载,只要我们能够通过堆溢出将ni->library覆盖为0,就会让程序调用nss_new_service函数让ni结构体重新初始化,刚初始化后的ni->library->lib_handle一定为0,所以会运行到下面的代码块,执行到__libc_dlopen 函数。
这里是漏洞利用的核心代码,接下来我们考虑如何实现精准的堆溢出来覆盖ni结构体,这就要提到nss机制,首先/etc/目录下有一个文件/etc/nsswitch.conf,来看看里面写了些啥
它规定了程序在查找so方法的时候采用何种途径和顺序
然后来看三个结构体的内容
1 | |
在__nss_database_lookup函数中,如果全局入口 service_table 为空,则会调用 nss_parse_file 进行初始化,相关代码如下:
1 | |
然后继续看nss_parse_file是如何实现的:
1 | |
到这里大概梳理一下程序逻辑,程序会打开/etc/nsswitch.conf,文件,读入内容并根据内容建立堆快结构,最后形成如下结构:
这七个chunk是在同一个函数中一次性申请出来的
除此之外,值得注意的是,在 nss_parse_file 函数中有一个 __getline 函数,该函数会根据读入内容的长度申请一个chunk,并且这个chunk 会在最后 nss_parse_file 函数返回时被释放。由于/etc/nsswitch.conf 里面内容格式基本最长的一行就是注释了,而且我们不可控该文件,所以这里可以认为每次 __getline 函数中申请的chunk 长度是一样的,固定为0x80大小。
所以我们可以将它理解为,这是一个在service 链表之前申请的,并且service链表结构申请完毕就会被释放的,而且在vuln chunk 申请之前还能一直保持free 状态的一个非常宝贵的chunk。
分析完这个函数,我们总得知道怎么触发它吧,当需要调用一些,查找用户或者主机信息的函数时,会执行以下流程:
void *
__nss_lookup_function (service_user *ni, const char *fct_name)
{
··· ···
found = __tsearch (&fct_name, &ni->known, &known_compare);
…. //没有搜到的一些操作省略
else
{
known_function *known = malloc (sizeof *known);
··· ···
else
{
//调用nss_load_library, 检查ni->library->lib_handle 是否为空,为空则重新dlopen
//具体nss_load_library 代码见上面
··· ···
if (nss_load_library (ni) != 0)
/* This only happens when out of memory. */
goto remove_from_tree;
if (ni->library->lib_handle == (void *) -1l)
/* Library not found => function not found. */
result = NULL;
else
{
··· ···
/* Construct the function name. */
__stpcpy (__stpcpy (__stpcpy (__stpcpy (name, “nss“),
ni->name),
“_”),
fct_name);
/* Look up the symbol. */
result = __libc_dlsym (ni->library->lib_handle, name);
}
··· ···
··· ···
}
……
return result;
}
libc_hidden_def (__nss_lookup_function)
可以看到就是在这里调用了nss_load_library (ni),也就是说只要调用了libnss_xx.so里的函数,就一定会调用nss_load_library来进行搜索。只需要知道堆溢出发生之后,第一个被调用的libnss相关的函数属于哪个so,然后通过堆布局将该so 所属的service_user 结构体布局到 vuln chunk 后面即可
分析完任意代码执行原理,再来谈谈如何进行堆布局,只有通过合理的堆布局,才能成功溢出到对应的结构体且不修改其他正常结构体。这里介绍一种方法:setlocale
setlocale 的堆机制,关键就一句话,按照自己想要释放的chunk 顺序去输入该长度的环境变量即可,能保证释放顺序和前后关系,但这些chunk 并不前后紧密相连
Setlocale是用来设置语言环境的,有几种环境变量参数,在sudo 中使用的是 setlocale(LC_ALL,“”); 当传入参数是LC_ALL 时,会从 LC_IDENTIFICATION 开始向前遍历所有的变量。对于每一个调用 _nl_find_locale 函数,这个函数里面比较复杂,但返回的 newnames[category] 其实就是对应环境变量的值,会在接下来调用strdup 函数将该字符串拷贝到堆上。由于传入的是LC_ALL ,那么会生成一个对应的字符串数组,接下来会和全局变量默认值进行一次校验,如果校验失败,那么就会将其释放(很容易构造出失败的输入)。
也就是说,我们可以通过构造一些合理长度的失败输入,实现任意次任意长度的堆申请和堆释放,这对我们的堆布局有非常大的帮助。
最后就是找到堆溢出之后第一个调用的nss里的函数,根据这个图找到它对应着几号chunk:
然后计算好参数总长度,让sudo申请到我们布置好的chunk,并且让接下来nss函数申请的chunk处在sudo申请的chunk的下方,然后利用sudo造成的堆溢出覆盖service_user结构体即可,name在service_user结构体偏移0x30的位置,覆盖成我们自己写的.so的name即可实现任意代码执行
1 | |
1 | |
编译命令:
1 | |
ref:https://blog.csdn.net/weixin_46483787/article/details/125552056
其他
个人介绍
各位面试官,你们好,我叫xxx,现就读于成都信息工程大学。也是道格安全研究实验室成员,现至力于二进制安全研究,热爱网络安全,愿意不断接触和学习新的专业技术和知识。在Github有多个实用开源工具与软件,也拥有多个项目经历和比赛证书。
曾经在奇安信、矢安科技、永信至成、启明星辰、绿盟科技、网御科技、51cto、易霖博等等知名安全公司的特聘岗位工作过。
目前希望入职漏洞挖掘相关的职位,谢谢。
你挖过哪些洞?
之前挖了华为官网的xss,2小时内还有效,准备提交的,被他们的waf检测到了,很快被修复了。
通过webbench可以对我们学校造成拒绝服务式攻击,导致数据库出现报错在前端。
某资源网站每日中午12点整时,访问https://www.aqiyuanma.com某某商品时,突然跳转到world presss安装界面,可以自己创建账号
,通过该账号可以访问后台,持续3分钟左右,又会自己跳出来。
小米手机热点转发syn洪水攻击时,会死机,测试过4个小米,三个会死机,一个严重卡顿,测试过一台华为,出现卡顿。
开源pev工具的洞。
开源JEngine热更框架的bug。
你还有什么想问的吗?
没了,谢谢!
打赏点小钱

